Mise à l'échelle avec PySpark
L’Architecture Moderne de PySpark
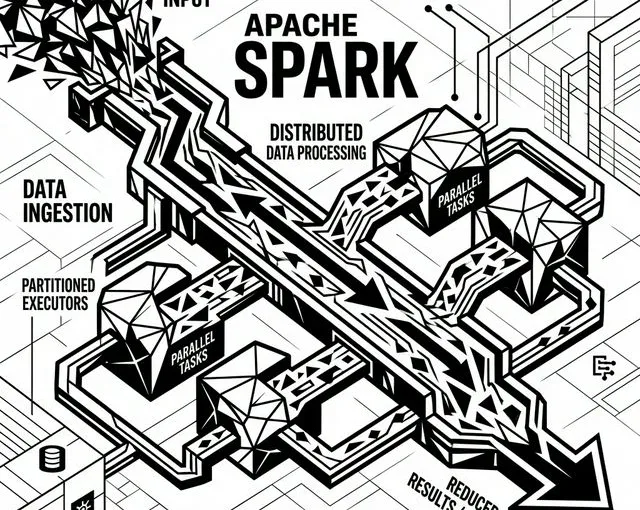
Lorsque les agences sont confrontées à des demandes analytiques atteignant des téraoctets, le traitement simple avec Pandas heurte un mur infranchissable. Entrez PySpark : l’interface Python pour Apache Spark.
Conçu spécifiquement autour d’un cadre de cluster, PySpark distribue les tâches de traitement de données de manière simultanée. En s’appuyant sur le calcul en mémoire, il exécute les algorithmes MapReduce beaucoup plus rapidement que les écosystèmes Hadoop classiques basés sur le disque.
Paradigmes Fondamentaux
- RDD (Resilient Distributed Datasets) : La logique fondamentale de Spark. Ce sont des collections distribuées immuables de morceaux de données partitionnés automatiquement sur votre cluster.
- DataFrames et SQL : Dans des versions plus récentes, PySpark a intégré les DataFrames, fournissant un système hautement optimisé, identique à la requête de tables SQL.
- Lazy Evaluation : PySpark n’exécute pas de lignage tant qu’une action spécifique n’est pas déclenchée (comme
.show()ou.write()). Cela lui permet d’optimiser le plan d’exécution physique complet en premier.
“Un moteur robuste ne se juge pas à ce qu’il peut calculer sur un serveur massif, mais à l’efficacité avec laquelle il dicte des calculs parallèles.”
Demlon déploie activement des pipelines PySpark via des réseaux Cloud-Native pour extraire des vitesses inégalées. L’informatique distribuée est la réponse définitive.