
Web Scraping With LlamaIndex & demlon: Full Python Guide
Throughout this guide, we’ll use LlamaIndex to extract data with their demlon tools . When you’re finished with this tutorial, you’ll be able to do all the following.
Extract website data as markdown
Take screenshots of webpages
Perform Google searches from inside your application
Trigger collections on demand using datafeeds and demlon’s Web Scraper API
Introduction: What is LlamaIndex?
Before the age of AI, data collection was a brittle and high maintenance process. A single change to the site layout could break your entire pipeline. In modern times, this isn’t the case — as long as you’re using the right tools.
LlamaIndex connects language models to external tooling and data sources. It comes prepacked with minimal models built to work minimally with these toolsets. In our case particularly, LlamaIndex can integrate with demlon’s MCP Server .
In the next few sections, we’ll walk through the capabilities of the demlon toolset from LlamaIndex. Make sure you’ve got Python installed.
Prerequisites
Our requirements here are surprisingly light. For simple scraping operations, we don’t even need an LLM. You need LlamaIndex and a demlon API key — that’s it!
LlamaIndex
LlamaIndex offers a full suite of tools you can install with the following command. If you’re only looking to scrape the web, this isn’t strictly required.
pip install llama-indexYou can install their demlon Tools with the following command via pip.
pip install llama-index-tools-demlondemlon
First, you need an account with demlon. You can use this link to sign up for a free trial with Unlocker. Once you’ve got an account, save your API key.
You can find your API key in your demlon “proxies” dashboard or in your user settings .

Finding Your API Key
Scraping With LlamaIndex
demlonToolSpec: Your Bridge To demlon MCP
LlamaIndex gives us access to the
demlonToolSpec
class. The snippet below sets up access to all of the tooling. Remember to replace the API key with your own and the zone name with one of your personal zones.
from llama_index.tools.demlon import demlonToolSpec
demlon = demlonToolSpec(
api_key="your-api-key",
zone="your-zone-name")Scrape As Markdown
The snippet below sets you up to scrape any page and return its content as markdown. The
scrape_as_markdown()
method does it all for us.
from llama_index.tools.demlon import demlonToolSpec
demlon = demlonToolSpec(
api_key="your-api-key",
zone="your-zone-name")
result = demlon.scrape_as_markdown(url="https://www.amazon.com")
print(result.text)Here’s some sample output from the command. As you can see, we’re successfully scraping Amazon data and converting it to markdown.

## Skip to
* [ Main content](#skippedLink)
---
## Keyboard shortcuts
* Search
alt + /
* Cart
shift + alt + C
* Home
shift + alt + H
* Orders
shift + alt + O
* Show/Hide shortcuts
shift + alt + Z
To move between items, use your keyboard's up or down arrows.
[ .us ](/ref=nav%5Flogo)
Delivering to Bothell 98011 Update location
All
Select the department you want to search in All Departments Alexa Skills All The Best Pets Amazon Autos Amazon Devices Amazon Fresh Amazon Global Store Amazon Haul Amazon One Medical Amazon Pharmacy Amazon Resale Appliances Apps & Games Arts, Crafts & Sewing Audible Books & Originals Automotive Parts & Accessories Baby Beauty & Personal Care Books CDs & Vinyl Cell Phones & Accessories Clothing, Shoes & Jewelry Women's Clothing, Shoes & Jewelry Men's Clothing, Shoes & Jewelry Girl's Clothing, Shoes & Jewelry Boy's Clothing, Shoes & Jewelry Baby Clothing, Shoes & Jewelry Collectibles & Fine Art Computers Credit and Payment Cards Digital Music Electronics Garden & Outdoor Gift Cards Grocery & Gourmet Food Handmade Health, Household & Baby Care Home & Business Services Home & Kitchen Industrial & Scientific Just for Prime Kindle Store Luggage & Travel Gear Luxury Stores Magazine Subscriptions Metropolitan Market Movies & TV Musical Instruments Office Products Pet Supplies Premium Beauty Prime Video Same-Day Store Smart Home Software Sports & Outdoors Subscribe & Save Subscription Boxes Tools & Home Improvement Toys & Games Under $10 Video Games Whole Foods Market
Search Amazon
[ EN ](/customer-preferences/edit?ie=UTF8&preferencesReturnUrl=%2F&ref%5F=topnav%5Flang)
[ Hello, sign in Account & Lists ](https://www.amazon.com/ap/signin?openid.pape.max%5Fauth%5Fage=0&openid.return%5Fto=https%3A%2F%2Fwww.amazon.com%2F%3F%5Fencoding%3DUTF8%26ref%5F%3Dnav%5Fya%5Fsignin&openid.identity=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier%5Fselect&openid.assoc%5Fhandle=usflex&openid.mode=checkid%5Fsetup&openid.claimed%5Fid=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier%5Fselect&openid.ns=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0)
[ Returns & Orders ](/gp/css/order-history?ref%5F=nav%5Forders%5Ffirst) [ 0 Cart ](/gp/cart/view.html?ref%5F=nav%5Fcart)
[ All ](/gp/site-directory?ref%5F=nav%5Fem%5Fjs%5Fdisabled)
* [Amazon Haul](/haul/store?ref%5F=nav%5Fcs%5Fhul%5Fdisb)
* [Medical Care ](https://health.amazon.com/prime?ref%5F=nav%5Fcs%5Fall%5Fhealth%5Fingress%5Fonem%5Fh)
* [Saks](/luxurystores/saks?ref%5F=nav%5Fcs%5Fsaks%5Fdisc)
* [Best Sellers](/gp/bestsellers/?ref%5F=nav%5Fcs%5Fbestsellers)
* [Amazon Basics](/Amazon%5FBasics?channel=discovbar&field-lbr%5Fbrands%5Fbrowse-bin=AmazonBasics&ref%5F=nav%5Fcs%5Famazonbasics)
* [New Releases](/gp/new-releases/?ref%5F=nav%5Fcs%5Fnewreleases)
* [Registry](/gp/browse.html?node=16115931011&ref%5F=nav%5Fcs%5Fregistry)
* [Groceries ](/fmc/learn-more?ref%5F=nav%5Fcs%5Fgroceries)
* [Today's Deals](/deals?ref%5F=nav%5Fcs%5Fgb)
* [Gift Cards ](/gift-cards/b/?ie=UTF8&node=2238192011&ref%5F=nav%5Fcs%5Fgc)
* [Smart Home](/Smart-Home/b/?ie=UTF8&node=6563140011&ref%5F=nav%5Fcs%5Fsmart%5Fhome)
* [Music](/music/player?ref%5F=nav%5Fcs%5Fmusic)
* [Prime ](/prime?ref%5F=nav%5Fcs%5Fprimelink%5Fnonmember)
* [Customer Service](/gp/help/customer/display.html?nodeId=508510&ref%5F=nav%5Fcs%5Ffs%5Fhub%5Fnavbar%5Fc)
* [Books](/books-used-books-textbooks/b/?ie=UTF8&node=283155&ref%5F=nav%5Fcs%5Fbooks)
* [Pharmacy](https://pharmacy.amazon.com/?nodl=0&ref%5F=nav%5Fcs%5Fpharmacy)
* [Luxury Stores](/luxurystores?ref%5F=nav%5Fcs%5Fluxury)
* [Amazon Home](/home-garden-kitchen-furniture-bedding/b/?ie=UTF8&node=1055398&ref%5F=nav%5Fcs%5Fhome)
* [Fashion](/amazon-fashion/b/?ie=UTF8&node=7141123011&ref%5F=nav%5Fcs%5Ffashion)
* [Toys & Games](/toys/b/?ie=UTF8&node=165793011&ref%5F=nav%5Fcs%5Ftoys)
* [Beauty & Personal Care](/Beauty-Makeup-Skin-Hair-Products/b/?ie=UTF8&node=3760911&ref%5F=nav%5Fcs%5Fbeauty)
* [Sell](/b/?%5Fencoding=UTF8&ld=AZUSSOA-sell&node=12766669011&ref%5F=nav%5Fcs%5Fsell)
* [Gift Shop](/gcx/Gifts-for-Everyone/gfhz/?ref%5F=nav%5Fcs%5Fgiftfinder)
* [Automotive](/automotive-auto-truck-replacements-parts/b/?ie=UTF8&node=15684181&ref%5F=nav%5Fcs%5Fautomotive)
* [Home Improvement](/Tools-and-Home-Improvement/b/?ie=UTF8&node=228013&ref%5F=nav%5Fcs%5Fhi)
* [Computers](/computer-pc-hardware-accessories-add-ons/b/?ie=UTF8&node=541966&ref%5F=nav%5Fcs%5Fpc)
* [Sports & Outdoors](/sports-outdoors/b/?ie=UTF8&node=3375251&ref%5F=nav%5Fcs%5Fsports)
[Prime Day is July 8-11](/primeday/?%5Fencoding=UTF8&ref%5F=nav%5Fswm%5FUS%5FPD25%5FLU%5FGW%5FSWM%5FAnnounce&pf%5Frd%5Fp=72020f4f-d636-4d60-9e39-399532eba237&pf%5Frd%5Fs=nav-sitewide-msg-text&pf%5Frd%5Ft=4201&pf%5Frd%5Fi=navbar-4201&pf%5Frd%5Fm=ATVPDKIKX0DER&pf%5Frd%5Fr=JA1EM1AGN54HEE871RFM) Taking Screenshots
Screenshots are another excellent tool when scraping the web. Most modern LLMs can view and interpret pictures. In the snippet below, we take a screenshot of the page with the
get_screenshot()
method.
from llama_index.tools.demlon import demlonToolSpec
demlon = demlonToolSpec(
api_key="your-api-key",
zone="your-zone-name")
result = demlon.get_screenshot(url="https://example.com", output_path="my-screenshot.png")
The shot below came from
demlonToolSpec
. This might be the easiest screenshot method available in all of Python.
Screenshot of example.com
Search Engine
Like the tools preceding it, we call the search engine using a simple method
search_engine()
. It uses Google by default, but you can use any search engine you want. You can learn more about our SERP query parameters
here
.
The following search engines are available.
Bing
Yandex
DuckDuckGo
from llama_index.tools.demlon import demlonToolSpec
demlon = demlonToolSpec(
api_key="your-api-key",
zone="mcp_unlocker")
result = demlon.search_engine(
query="Top News Articles"
)
with open("output.json", "w") as file:
json.dump(json.loads(result.json()), file, indent=4)
Notice how we’re calling
json.loads()
before dumping the data to a JSON file. Even when using
.json()
, LlamaIndex outputs its JSON as a string. If you wish to handle it like a
dict
,
json.loads()
converts it to a traditional JSON object for you.
Here’s a small portion of the JSON file that our scraper writes.
{
"id_": "34bcf1ea-998a-48ce-beb2-0d6feff950e1",
"embedding": null,
"metadata": {
"query": "Top News Articles",
"engine": "google",
"url": "https://www.google.com/search?q=Top%20News%20Articles&num=10"
},
"excluded_embed_metadata_keys": [],
"excluded_llm_metadata_keys": [],
"relationships": {},
"metadata_template": "{key}: {value}",
"metadata_separator": "\n",
"text_resource": {
"embeddings": null,
"text": "# Accessibility Links\n\nSkip to main content[Accessibility help](https://support.google.com/websearch/answer/181196?hl=en)\n\nAccessibility feedback\n\n[](https://www.google.com/webhp?hl=en&ictx=0&sa=X&ved=0ahUKEwizmMaNvoCOAxUmmYkEHa58MagQpYkNCAo)\n\nPress / to jump to the search box\n\nTop News Articles\n\n[Sign in](https://accounts.google.com/ServiceLogin?hl=en&passive=true&continue=https://www.google.com/search%3Fq%3DTop%2BNews%2BArticles%26num%3D10%26oq%3DTop%2BNews%2BArticles%26uule%3Dw%2BCAIQICINVW5pdGVkIFN0YXRlcw%26hl%3Den%26sourceid%3Dchrome%26ie%3DUTF-8&ec=GAZAAQ)\n\n# Filters and Topics\n\n[AI Mode](/search?q=Top+News+Articles&sca%5Fesv=62890ff6c1b2e448&hl=en&udm=50&Web Scraper API
The
scraping API
allows you to create data feeds that trigger collections on demand. In the code below, we use
web_data_feed()
to trigger a collection from the Scraper API.
from llama_index.tools.demlon import demlonToolSpec
demlon = demlonToolSpec(
api_key="your-api-key",
zone="mcp_unlocker")
result = demlon.web_data_feed(
source_type="linkedin_person_profile",
url="https://www.linkedin.com/in/williamhgates/",
timeout=600,
polling_interval=30)
print(result)After a few moments, head on over to your logs page . You should see all of your collections logged and ready to download with the click of a button.
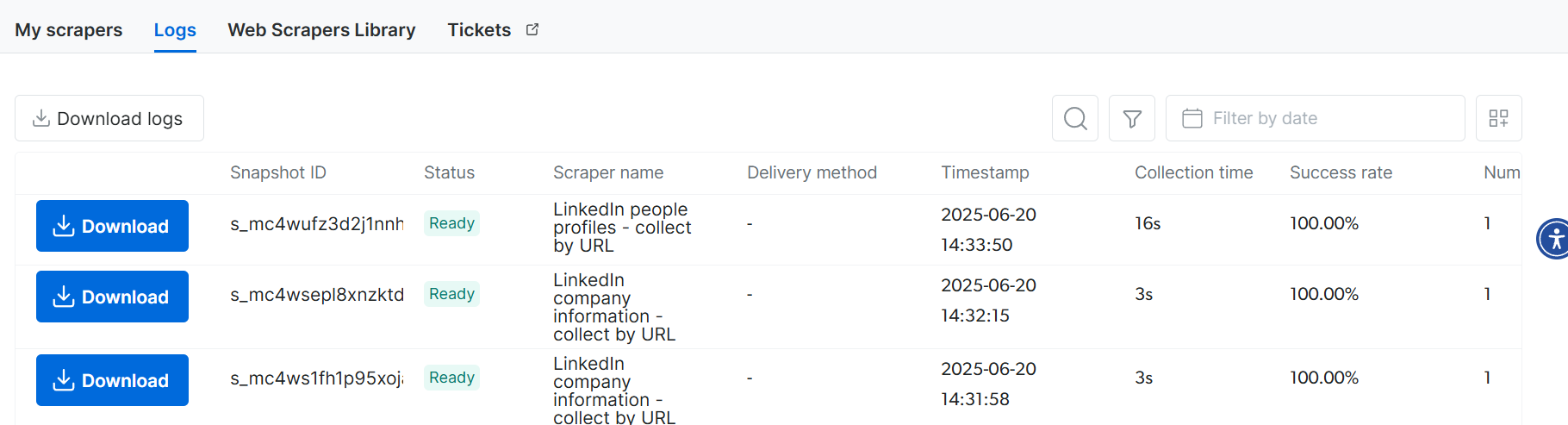
Scraper Reports Are Ready To Download
Conclusion
Now, you’ve leveled up your web scraping and cut your workload drastically. With LlamaIndex, demlon and just a few lines of Python, you can pull almost any data you want from the web.
Whether you’re extracting markdown, capturing screenshots, running Google searches or triggering full scraping jobs, LlamaIndex and demlon give you the power to harvest your valuable data.
Ready to take it to the next level? Hook this power tool combo into a live data pipeline or build an AI agent.
Sign up for a free trial now and level up your data collection today!