
Using Cheerio NPM for Web Scraping
Node.js has emerged as a powerful option for building web scrapers, offering convenience for both client-side and server-side developments. Its extensive catalog of libraries makes web scraping with Node.js a breeze. In this article, cheerio will be spotlighted, and its capabilities will be explored for efficient web scraping.
Cheerio is a fast and flexible library for parsing and manipulating HTML and XML documents. It implements a subset of jQuery features, which means anyone familiar with jQuery will find themselves at home with the syntax of cheerio. Under the hood, cheerio uses the
parse5
and, optionally, the
htmlparser2
libraries for parsing HTML and XML documents.
In this article, you’ll create a project that uses cheerio and learn how to scrape data from dynamic websites and static web pages.
Web Scraping with cheerio
Before you begin this tutorial, make sure you have Node.js installed on your system. If you don’t have it already, you can install it using the official documentation .
Once you’ve installed Node.js, create a directory called
cheerio-demo
and
cd
into it:
mkdir cheerio-demo && cd cheerio-demo
Then initialize an npm project in the directory:
npm init -y
Install the cheerio and Axios packages:
npm install cheerio axios
Create a file called
index.js
, which is where you’ll be writing the code for this tutorial. Then open this file in your favorite editor to get started.
The first thing you need to do is to import the required modules:
const axios = require("axios");
const cheerio = require("cheerio");
In this tutorial, you’ll scrape the
Books to Scrape page
, a public sandbox for testing web scrapers. First you’ll use Axios to make a
GET
request to the web page with the following code:
axios.get("https://books.toscrape.com/").then((response) => {
});
The
response
object in the callback contains the HTML code of the web page in the
data
property. This HTML needs to be passed to the
load
function of the
cheerio
module. This function returns an instance of
CheerioAPI
, which will be used to access and manipulate the DOM for the rest of the code. Note that the
CheerioAPI
instance is stored in a variable named
$
, which is a nod to the jQuery syntax:
axios.get("https://books.toscrape.com/").then((response) => {
const $ = cheerio.load(response.data);
});
Finding Elements
cheerio supports using CSS and XPath selectors for selecting elements from the page. If you’ve used jQuery, you’ll find the syntax familiar—pass the CSS selector to the
$()
function. Use this syntax to find and extract information on the first page of the Books to Scrape website.
Visit
https://books.toscrape.com/
and open up the Developer Console. Search the
Inspect Element
tab, where you’ll learn more about the HTML structure of the page. In this case, you can see that all the information about the books is contained in
article
tags with the class
product-pod
:
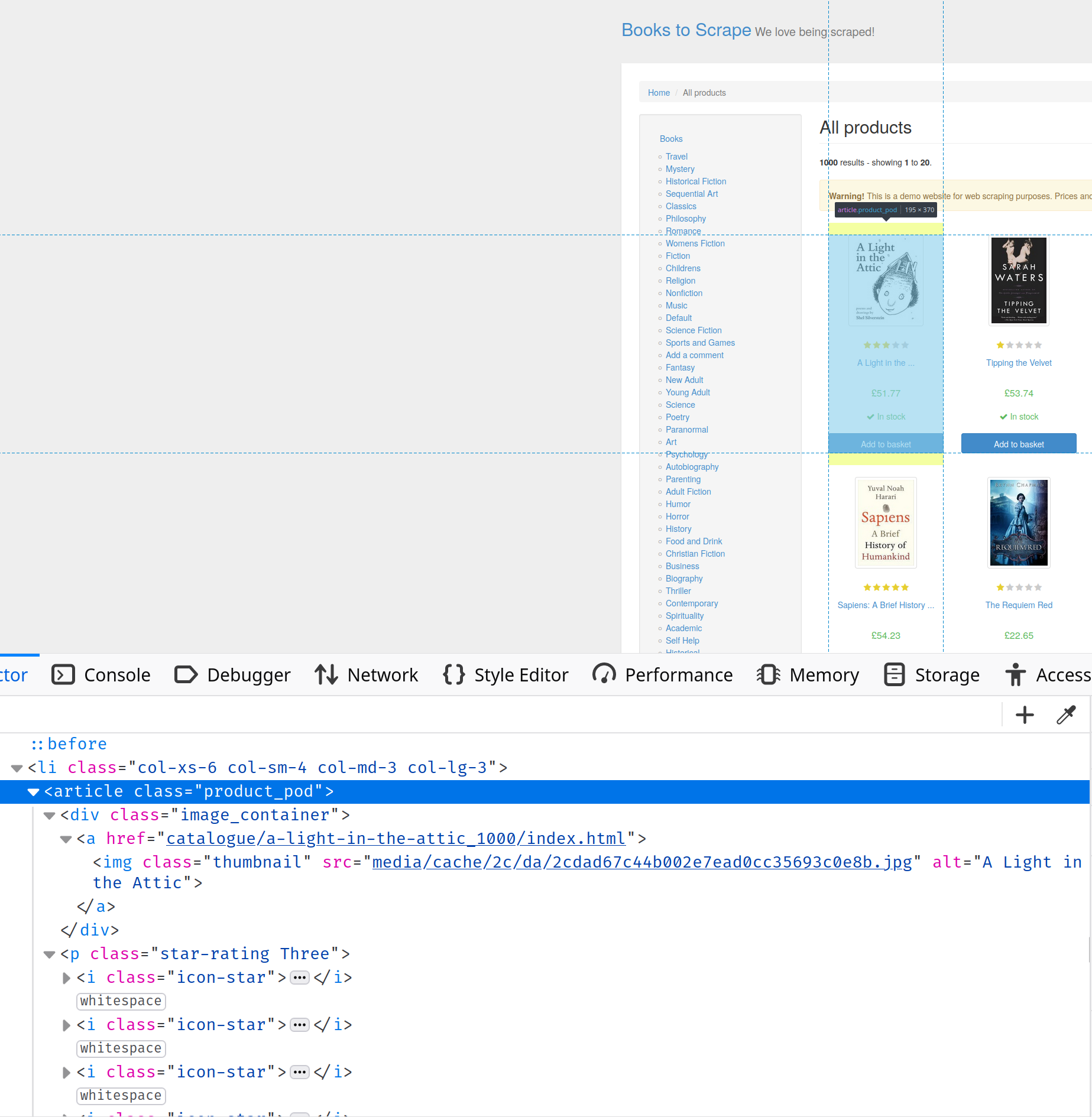
Inspect element
To select the books, you need to use the
article.product_pod
CSS selector like this:
$("article.product_pod");
This function returns a list of all the elements that match the selector. You can use the
each
method to iterate over the list:
$("article.product_pod").each( (i, element) => {
});
Inside the loop, you can use the
element
variable to extract the data.
Try to extract the title of the books on the first page. Going back to the Inspect Element console, you can see how the titles are stored:

inspect title elements
You see that you need to find an
h3
, which is a child of the
element
variable. Inside the
h3
, there is an
a
element that holds the book’s title. You can use the
find
method with a CSS selector to find the children of an element, but initially, you need to pass
element
through
$
to convert it into an instance of
Cheerio
:
$("article.product_pod").each( (i, element) => {
const titleH3 = $(element).find("h3");
});
Now, you can find the
a
inside
titleH3
:
$("article.product_pod").each( (i, element) => {
const titleH3 = $(element).find("h3");
const title = titleH3.find("a");
});
Note:
titleH3
is already an instance of
Cheerio
, so you don’t need to pass it through
$
.
Note:
titleH3
is already an instance of
Cheerio
, so you don’t need to pass it through
$
.
Extracting Text
Once you’ve selected an element, you can get the text of that element using the
text
method.
Modify the previous example to extract the book’s title by calling the
text
method on the result of the
find
method:
$("article.product_pod").each( (i, element) => {
const titleH3 = $(element).find("h3");
const title = titleH3.find("a").text();
console.log(title);
});
The complete code should look like this:
const axios = require("axios");
const cheerio = require("cheerio");
axios.get("https://books.toscrape.com/").then((response) => {
const $ = cheerio.load(response.data);
$("article.product_pod").each( (i, element) => {
const titleH3 = $(element).find("h3");
const title = titleH3.find("a").text();
console.log(title);
});
});
Run the code with
node index.js
, and you should see the following output:
A Light in the ...
Tipping the Velvet
Soumission
Sharp Objects
Sapiens: A Brief History ...
The Requiem Red
The Dirty Little Secrets ...
The Coming Woman: A ...
The Boys in the ...
The Black Maria
Starving Hearts (Triangular Trade ...
Shakespeare's Sonnets
Set Me Free
Scott Pilgrim's Precious Little ...
Rip it Up and ...
Our Band Could Be ...
Olio
Mesaerion: The Best Science ...
Libertarianism for Beginners
It's Only the Himalayas
Navigating the DOM: Finding Children and Siblings
Once you’ve extracted the titles, it’s time to extract the price and availability of each book. The
Inspect Element
reveals that both the price and availability are stored in a
div
with the class
product_price
. You can select this
div
with the
.product_price
CSS selector, but since you’ve already covered CSS selectors, the following will discuss another way to do this:
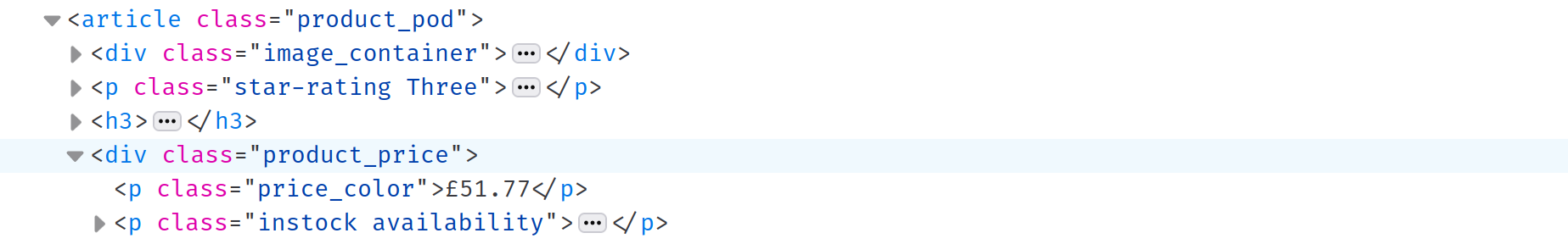
Finding children and siblings code
Note:
The
div
is a sibling of the
titleH3
you selected previously. By calling the
next
method of
titleH3
, you can select the next sibling:
Note:
The
div
is a sibling of the
titleH3
you selected previously. By calling the
next
method of
titleH3
, you can select the next sibling:
const priceDiv = titleH3.next();
You’ve already seen that you can use the
find
method to find the children of an element based on CSS selectors. You can also select all the children with the
children
method and then use the
eq
method to select a particular child. This is equivalent to the
nth-child
CSS selector.
In this case, the price is the first child of
priceDiv
, and the availability is the second child of
priceDiv
. This means you can select them with
priceDiv.children().eq(0)
and
priceDiv.children().eq(1)
, respectively. Do that and print the price and availability:
$("article.product_pod").each( (i, element) => {
const titleH3 = $(element).find("h3");
const title = titleH3.find("a").text();
const priceDiv = titleH3.next();
const price = priceDiv.children().eq(0).text().trim();
const availability = priceDiv.children().eq(1).text().trim();
console.log(title, price, availability);
});
Now, running the code shows the following output:
A Light in the ... £51.77 In stock
Tipping the Velvet £53.74 In stock
Soumission £50.10 In stock
Sharp Objects £47.82 In stock
Sapiens: A Brief History ... £54.23 In stock
The Requiem Red £22.65 In stock
The Dirty Little Secrets ... £33.34 In stock
The Coming Woman: A ... £17.93 In stock
The Boys in the ... £22.60 In stock
The Black Maria £52.15 In stock
Starving Hearts (Triangular Trade ... £13.99 In stock
Shakespeare's Sonnets £20.66 In stock
Set Me Free £17.46 In stock
Scott Pilgrim's Precious Little ... £52.29 In stock
Rip it Up and ... £35.02 In stock
Our Band Could Be ... £57.25 In stock
Olio £23.88 In stock
Mesaerion: The Best Science ... £37.59 In stock
Libertarianism for Beginners £51.33 In stock
It's Only the Himalayas £45.17 In stock
Accessing Attributes
So far, you’ve navigated the DOM and extracted texts from the elements. It’s also possible to extract attributes from an element using cheerio, which is what you’ll do in this section. Here, you’ll extract the rating of books by reading the class list of elements.
The rating of the books has an interesting structure. The ratings are contained in a
p
tag. Each
p
tag has exactly five stars, but the stars are colored using CSS based on the class name of the
p
element. For example, in a
p
with class
star-rating.Four
, the first four stars are colored yellow, denoting a four-star rating:

Star ratings code
To extract the rating of a book, you need to extract the class names of the
p
element. The first step is to find the paragraph containing the rating:
const ratingP = $(element).find("p.star-rating");
By passing the attribute name to the
attr
method, you can read the attributes of an element. In this case, you need to read the class list, which is demonstrated in the following code:
const starRating = ratingP.attr('class');
The class list is in the following form:
star-rating X
, where
X
is one of
One
,
Two
,
Three
,
Four
, and
Five
. This means you need to split the class list on space and take the second element. The following code does that and converts the textual rating into a numerical rating:
const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(" ")[1]];
If you put everything together, your code will look like this:
$("article.product_pod").each( (i, element) => {
const titleH3 = $(element).find("h3");
const title = titleH3.find("a").text();
const priceDiv = titleH3.next();
const price = priceDiv.children().eq(0).text().trim();
const availability = priceDiv.children().eq(1).text().trim();
const ratingP = $(element).find("p.star-rating");
const starRating = ratingP.attr('class');
const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(" ")[1]];
console.log(title, price, availability, rating);
});
The output looks like this:
A Light in the ... £51.77 In stock 3
Tipping the Velvet £53.74 In stock 1
Soumission £50.10 In stock 1
Sharp Objects £47.82 In stock 4
Sapiens: A Brief History ... £54.23 In stock 5
The Requiem Red £22.65 In stock 1
The Dirty Little Secrets ... £33.34 In stock 4
The Coming Woman: A ... £17.93 In stock 3
The Boys in the ... £22.60 In stock 4
The Black Maria £52.15 In stock 1
Starving Hearts (Triangular Trade ... £13.99 In stock 2
Shakespeare's Sonnets £20.66 In stock 4
Set Me Free £17.46 In stock 5
Scott Pilgrim's Precious Little ... £52.29 In stock 5
Rip it Up and ... £35.02 In stock 5
Our Band Could Be ... £57.25 In stock 3
Olio £23.88 In stock 1
Mesaerion: The Best Science ... £37.59 In stock 1
Libertarianism for Beginners £51.33 In stock 2
It's Only the Himalayas £45.17 In stock 2
Saving the Data
After scraping the data from the web page, you’d generally want to save it. There are several ways you can do this, such as saving to a file, saving to a database, or feeding it to a data processing pipeline. In this section, you’ll learn the simplest of all—saving data in a CSV file.
To do so, install the
node-csv
package:
npm install csv
In
index.js
, import the
fs
and
csv-stringify
modules:
const fs = require("fs");
const { stringify } = require("csv-stringify");
To write a local file, you need to create a
WriteStream
:
const filename = "scraped_data.csv";
const writableStream = fs.createWriteStream(filename);
Declare the column names, which are added to the CSV file as headers:
const columns = [
"title",
"rating",
"price",
"availability"
];
Create a stringifier with the column names:
const stringifier = stringify({ header: true, columns: columns });
Inside the
each
function, you’ll use
stringifier
to write the data:
$("article.product_pod").each( (i, element) => {
...
const data = { title, rating, price, availability };
stringifier.write(data);
});
Finally, outside the
each
function, you need to write the contents of
stringifier
into the
writableStream
variable:
stringifier.pipe(writableStream);
At this point, your code should look like this:
const axios = require("axios");
const cheerio = require("cheerio");
const fs = require("fs");
const { stringify } = require("csv-stringify");
const filename = "scraped_data.csv";
const writableStream = fs.createWriteStream(filename);
const columns = [
"title",
"rating",
"price",
"availability"
];
const stringifier = stringify({ header: true, columns: columns });
axios.get("https://books.toscrape.com/").then((response) => {
const $ = cheerio.load(response.data);
$("article.product_pod").each( (i, element) => {
const titleH3 = $(element).find("h3");
const title = titleH3.find("a").text();
const priceDiv = titleH3.next();
const price = priceDiv.children().eq(0).text().trim();
const availability = priceDiv.children().eq(1).text().trim();
const ratingP = $(element).find("p.star-rating");
const starRating = ratingP.attr('class');
const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(" ")[1]];
console.log(title, price, availability, rating);
const data = { title, rating, price, availability };
stringifier.write(data);
});
stringifier.pipe(writableStream);
});
Run the code, and it should create a
scraped_data.csv
file with the scraped data inside:
title,rating,price,availability
A Light in the ...,3,£51.77,In stock
Tipping the Velvet,1,£53.74,In stock
Soumission,1,£50.10,In stock
Sharp Objects,4,£47.82,In stock
Sapiens: A Brief History ...,5,£54.23,In stock
The Requiem Red,1,£22.65,In stock
The Dirty Little Secrets ...,4,£33.34,In stock
The Coming Woman: A ...,3,£17.93,In stock
The Boys in the ...,4,£22.60,In stock
The Black Maria,1,£52.15,In stock
Starving Hearts (Triangular Trade ...,2,£13.99,In stock
Shakespeare's Sonnets,4,£20.66,In stock
Set Me Free,5,£17.46,In stock
Scott Pilgrim's Precious Little ...,5,£52.29,In stock
Rip it Up and ...,5,£35.02,In stock
Our Band Could Be ...,3,£57.25,In stock
Olio,1,£23.88,In stock
Mesaerion: The Best Science ...,1,£37.59,In stock
Libertarianism for Beginners,2,£51.33,In stock
It's Only the Himalayas,2,£45.17,In stock
Conclusion
As you’ve seen here, the cheerio library makes web scraping easy with its jQuery-esque syntax and blazing-fast operation. In this article, you learned how to do the following:
Load and parse an HTML web page with cheerio
Find elements with CSS selectors
Extract data from elements
Navigate the DOM
Save scraped data into local file storage
You can find the complete code on GitHub .
However, cheerio is just an HTML parser, so it can’t execute JavaScript code. That means you can’t use it for scraping dynamic web pages and single-page applications. To scrape those, you need to look beyond cheerio at complex tools like Selenium or Playwright. And that’s where Bright Data comes in. Bright Data’s vast web scraping solutions include a Selenium Scraping Browser and Playwright Scraping Browser . To learn more about the products, you may visit our Scraping Browser documentation .
Scraping Browser free trial
Scraping Browser free trial