
MCP vs Traditional Web Scraping: AI or Code in 2025?
Imagine this: You’ve spent weeks perfecting your web scraper. CSS selectors are fine-tuned, the data flows smoothly, and then Amazon changes its layout. Your carefully refined selectors break overnight. Sound familiar?
Enter the Model Context Protocol (MCP), a new approach that promises to change how we extract web data. Instead of writing brittle CSS selectors, you give plain-English instructions to an AI that handles the heavy lifting. But is this AI-driven approach really better than battle-tested traditional methods?
Let’s dive deep into both approaches, build some real scrapers, and find out which method wins in 2025.
Quick Comparison: Traditional vs. MCP Scraping
Before we dive into the details, here’s what sets these approaches apart:
| Aspect | Traditional Scraping | MCP-Powered Scraping |
|---|---|---|
| Setup Time | Hours to days | Minutes to hours |
| Maintenance | High – breaks with layout changes | Lower – AI adapts to minor changes |
| Cost | Lower per request | Higher per request |
| Control | Complete control over logic | Relies on AI interpretation |
| Learning Curve | Steep – requires coding skills | Gentler – natural language prompts |
| Best For | High-volume, stable sites | Rapid prototyping, changing sites |
Traditional Web Scraping: The Foundation
Traditional web scraping has powered data extraction for decades. At its core, it’s a straightforward four-step process that gives you complete control over how data is extracted.
The Traditional Workflow
Send HTTP Requests:
Start with an HTTP client to fetch web pages. Python’s
requests
library handles basic needs, but for serious performance, consider:
httpx
or
aiohttp
for async operations
requests-futures
for parallel requests
Check out our guide on
making web scraping faster
for optimization tips
Parse the HTML: Transform raw HTML into workable data using a parser. BeautifulSoup remains the go-to choice, often powered by lxml for speed. These parsers excel at static content extraction.
Extract Your Data: Target specific elements using: CSS selectors for straightforward selection by class, ID, or attributes XPath for complex traversals and text matching Not sure which to use? Our XPath vs CSS selectors guide breaks it down
httpx or aiohttp for async operations
requests-futures for parallel requests
Check out our guide on making web scraping faster for optimization tips
CSS selectors for straightforward selection by class, ID, or attributes
XPath for complex traversals and text matching
Not sure which to use? Our XPath vs CSS selectors guide breaks it down
4. Handle Dynamic Content: For JavaScript-heavy sites, you’ll need browser automation:
Selenium : The veteran choice with broad language support
Playwright : Modern, fast, and reliable
Puppeteer : Perfect for Node.js workflows
Bright Data’s Scraping Browser : Built-in anti-bot protection and proxy management
Popular Traditional Scraping Stacks
For Static Sites:
Python:
requests
+ Beautiful Soup
Node.js:
axios
+
Cheerio
Go: Colly
For Complex Crawling:
Python: Scrapy framework
For JavaScript-Heavy Sites:
Playwright + Playwright Stealth
Puppeteer + puppeteer-extra-plugin-stealth
SeleniumBase
Model Context Protocol: AI-Powered Scraping
Released by Anthropic on November 25, 2024, the Model Context Protocol (MCP) is an open standard that allows large language models (LLMs) to invoke external tools as easily as calling a function—think of it as USB-C for AI apps.
Instead of hard-coding HTTP requests or CSS selectors, you simply describe the outcome—“Grab the product title, price, and rating from this URL”—and the LLM selects the appropriate tool (e.g.,
scrape_product()
) behind the scenes.
For web scraping teams, this shift transforms brittle parsing logic into resilient, prompt-driven workflows.
How MCP Works
All messages travel over JSON-RPC 2.0 , making every call language-agnostic and stream-friendly.
Hosts — LLM applications (e.g., Claude Desktop) that start the conversation
Clients — protocol handlers embedded in the host
Servers — services that expose one or more tools
Tools — named functions returning structured results such as JSON or CSV
The magic happens in the interaction flow:
Describe the task. “Fetch the price history for this Nike shoe.”
LLM selects a tool. It maps your request to scrape_product_history(url) .
Server executes. Headless browsing, proxy rotation, and CAPTCHA solving—based on how the tool was configured.
Structured output. The LLM receives clean JSON and returns it or pipes it onward.
💡 Keep in mind: MCP governs any tool call, not just web extraction. It can orchestrate SQL queries, git operations, file I/O, and more. But someone still has to write the tool. The AI can’t invent logic that hasn’t been implemented.
Take a deeper look at how MCP revolutionizes web scraping workflows .
Official MCP SDKs
The Model Context Protocol organization provides SDKs for major languages:
TypeScript SDK – Primary implementation
Python SDK – Full-featured for AI/ML workflows
Java SDK – Maintained with Spring AI
C# SDK – Microsoft partnership (preview)
Ruby SDK – Shopify collaboration
Rust SDK – High-performance implementation
Kotlin SDK – JVM-based, great for Android
Head-to-Head: Building an Amazon Scraper Both Ways
Let’s build the same Amazon product scraper using both approaches. This practical comparison will highlight the real differences between traditional and MCP-powered scraping.
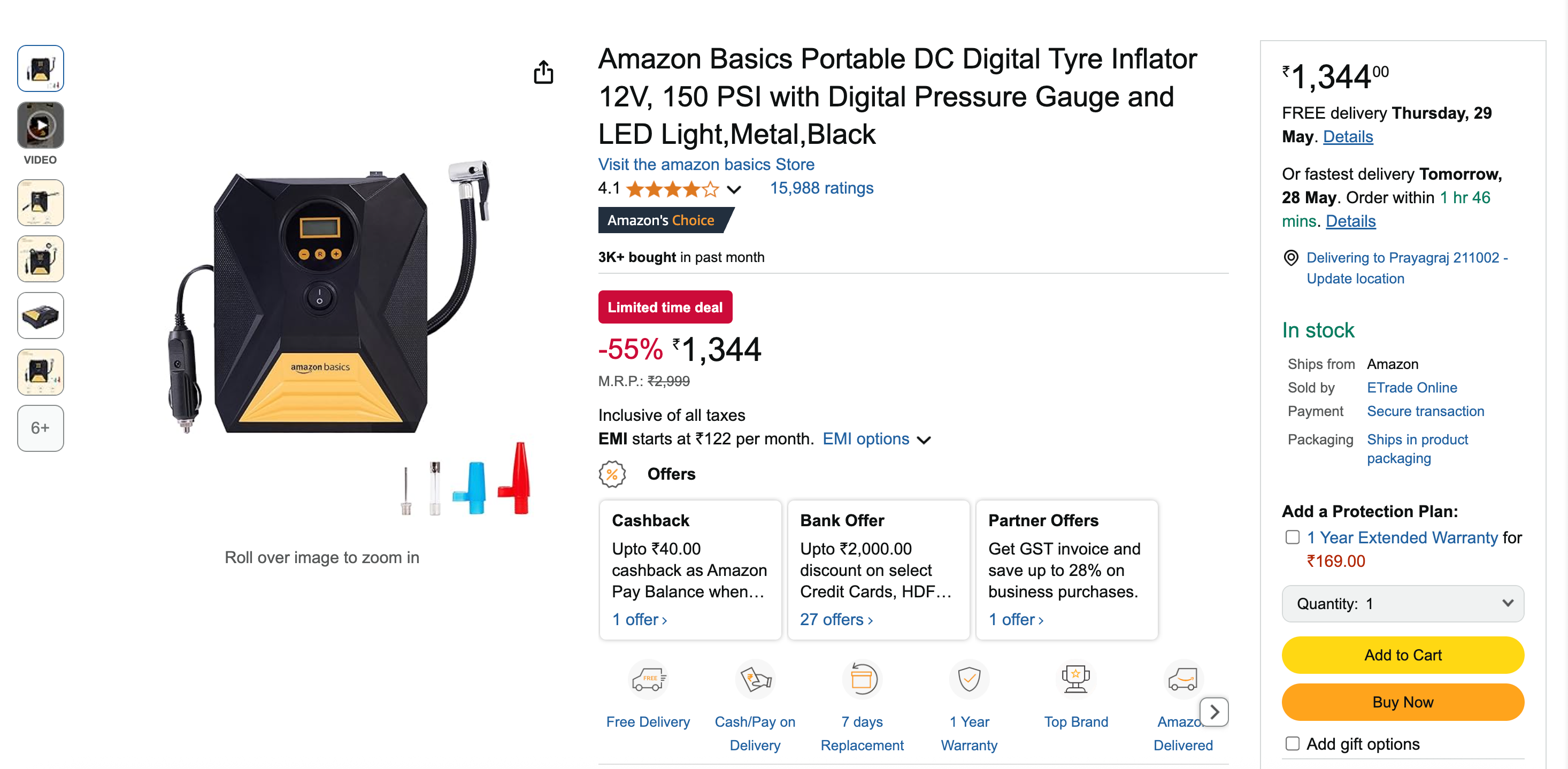
amazon-product-page
Traditional Approach
First, let’s build a traditional scraper using Playwright and BeautifulSoup:
import asyncio
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
async def scrape_amazon_product(url):
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
await page.goto(url)
await page.wait_for_selector("#productTitle", timeout=10000)
soup = BeautifulSoup(await page.content(), "html.parser")
await browser.close()
def extract(selector, default="N/A", attr=None, clean=lambda x: x.strip()):
element = soup.select_one(selector)
if not element:
return default
value = element.get(attr) if attr else element.text
return clean(value) if value else default
return {
"title": extract("#productTitle"),
"current_price": extract(".a-price-whole"),
"original_price": extract(".a-price.a-text-price span"),
"rating": extract("#acrPopover", attr="title"),
"reviews": extract("#acrCustomerReviewText"),
"availability": extract(
"#availability span", clean=lambda x: x.strip().split("n")[0].strip()
),
}
async def main():
product = await scrape_amazon_product("https://www.amazon.in/dp/B0BTDDVB67")
print("nProduct Information:")
print("-------------------")
print("n".join(f"{k.replace('_', ' ').title()}: {v}" for k, v in product.items()))
if __name__ == "__main__":
asyncio.run(main())
The Challenge
: Those CSS selectors (
#productTitle
,
.a-price-whole
) are hardcoded. The moment Amazon tweaks its HTML, your scraper breaks. You’ll spend more time fixing broken selectors than analyzing data.
Need to bypass Amazon’s anti-bot protections? Explore our full guide on bypassing Amazon CAPTCHA .
MCP Approach
Now let’s build the same scraper using MCP.
from mcp.server.fastmcp import FastMCP
from playwright.async_api import async_playwright
from markdownify import markdownify as md
from bs4 import BeautifulSoup
# Initialize FastMCP instance
mcp = FastMCP("Amazon Scraper")
@mcp.tool()
async def scrape_product(url: str) -> str:
"""
Fetch an Amazon product page, extract the main product section,
and return it as Markdown.
"""
browser = None
try:
async with async_playwright() as playwright:
# Launch headless browser
browser = await playwright.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate and wait for the product title
await page.goto(url, timeout=90000)
await page.wait_for_selector("span#productTitle", timeout=30000)
# Extract HTML and parse
html_content = await page.content()
soup = BeautifulSoup(html_content, "lxml")
product_section = soup.find("div", id="dp") or soup.body
return md(str(product_section)).strip()
except Exception as e:
return f"Error: {e}"
finally:
if browser is not None:
await browser.close()
if __name__ == "__main__":
mcp.run(transport="stdio")The Difference : Notice what’s missing? No specific selectors for price, rating, or availability. The MCP server just provides the content, and the AI figures out what to extract based on your natural language request.
Setting Up MCP with Cursor
Want to try this yourself? Here’s how to integrate your MCP server with Cursor:
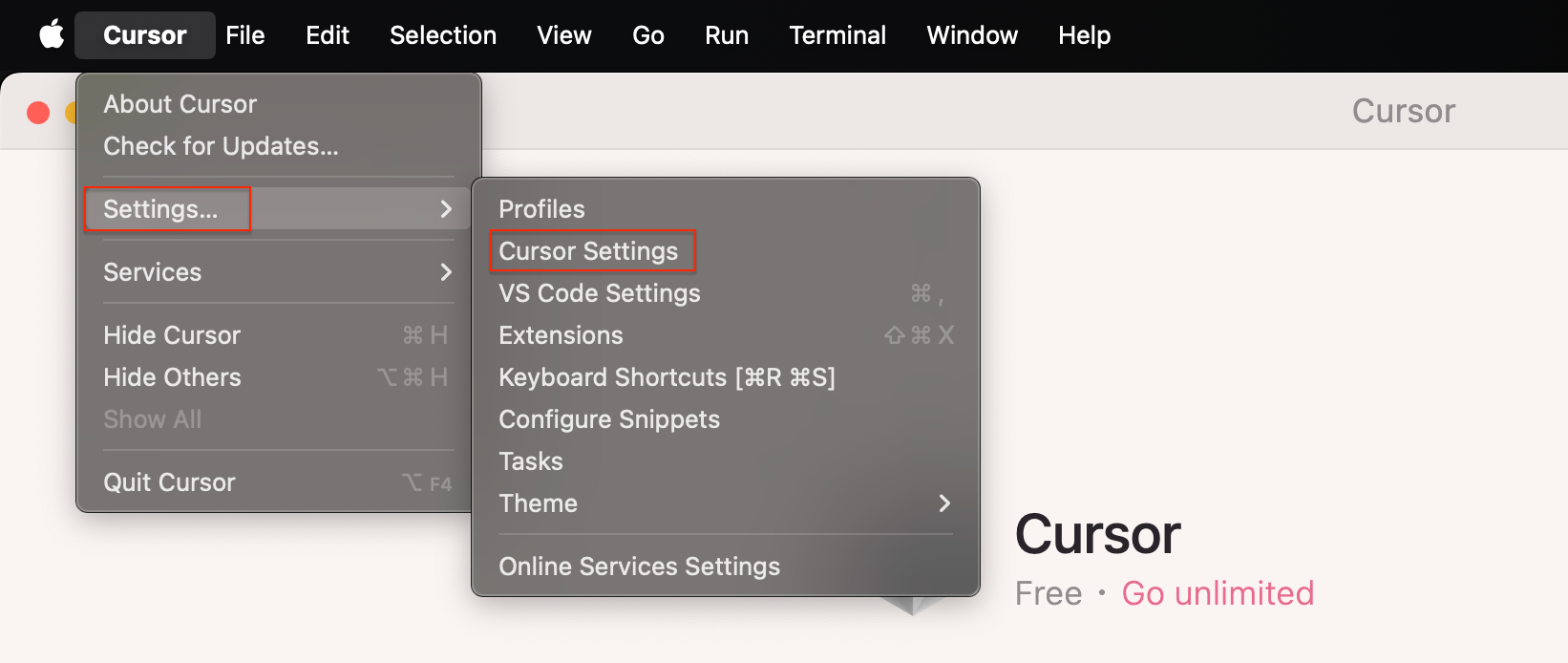
cursor-settings-menu
Step 1: Open Cursor and navigate to Settings → Cursor Settings
Step 2: Select MCP in the sidebar
Step 3: Click + Add new global MCP server
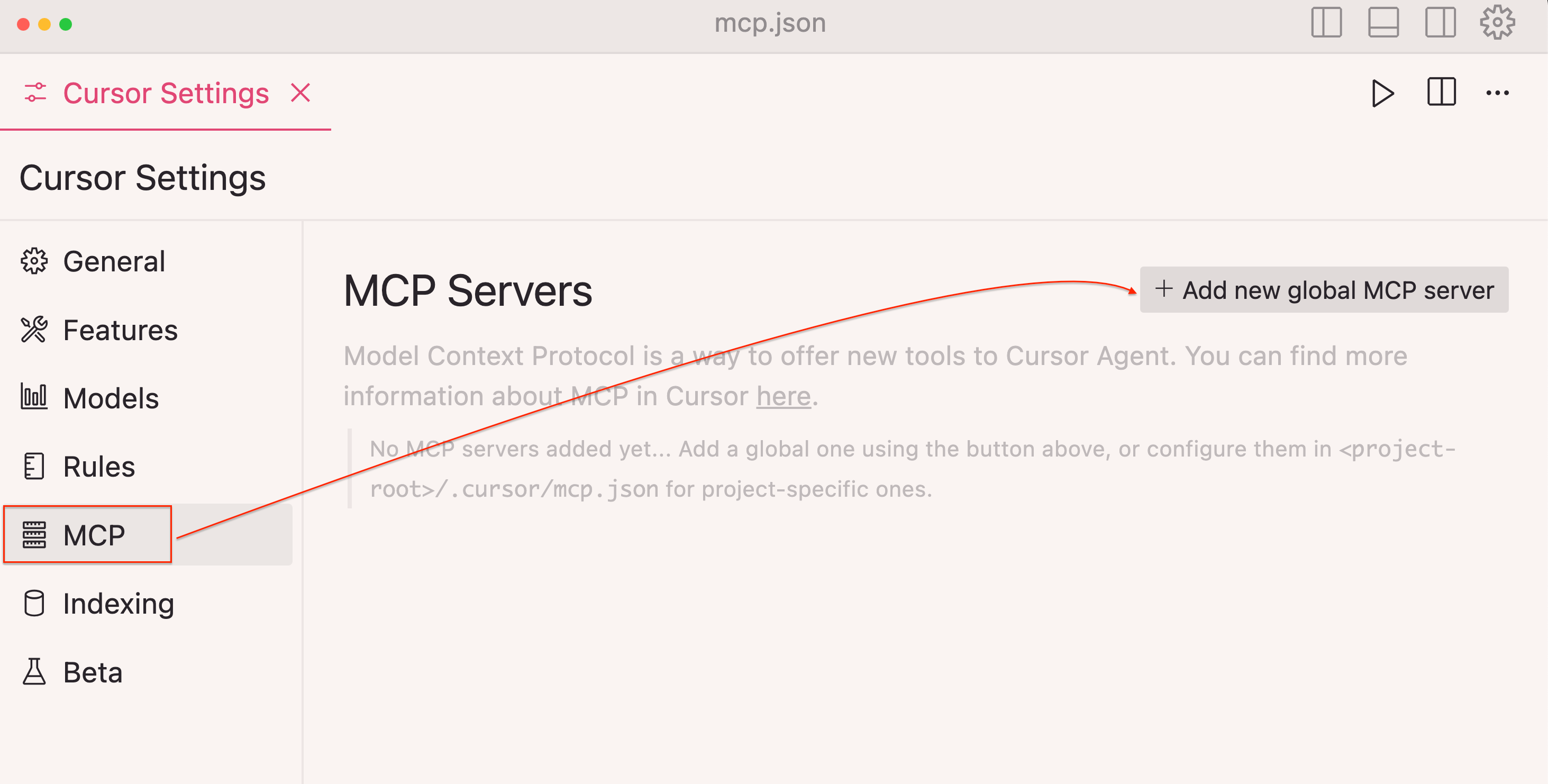
mcp-configuration-screen
Step 4: Add your server configuration:
{
"mcpServers": {
"amazon_product_scraper": {
"command": "/path/to/python",
"args": ["/path/to/amazon_scraper_mcp.py"]
}
}
}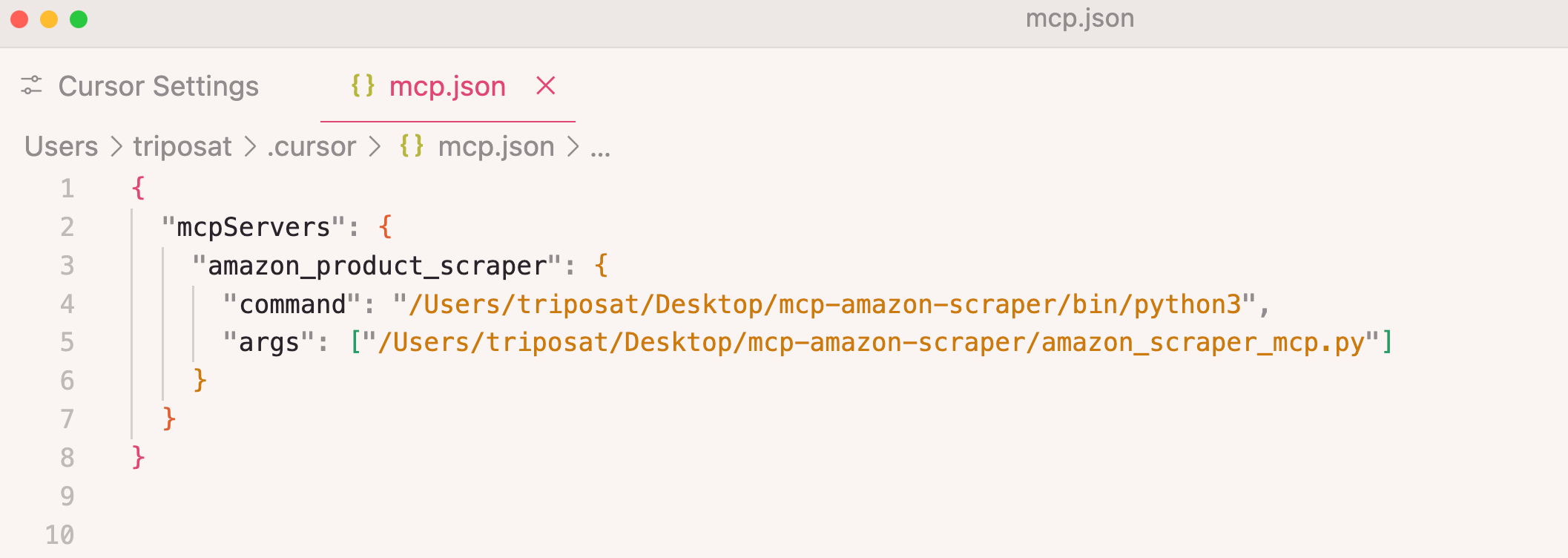
json-configuration-editor
Step 5: Save and verify that the connection shows green
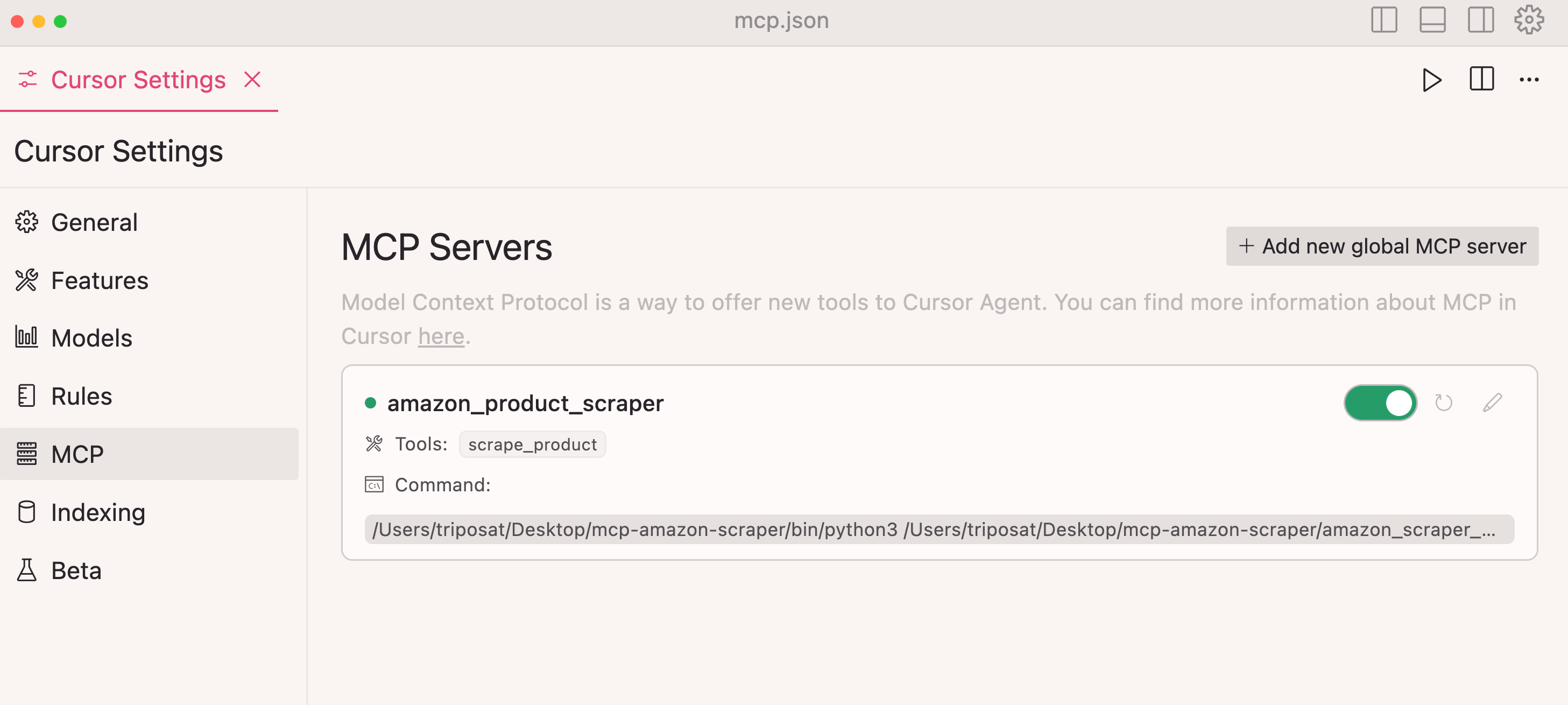
mcp-server-connected-status
Step 6: Now you can use natural language in Cursor’s chat:
Extract the product title, current price, original price, star rating, review count, three key features, and availability from https://www.amazon.in/dp/B0BTDDVB67 and return as JSON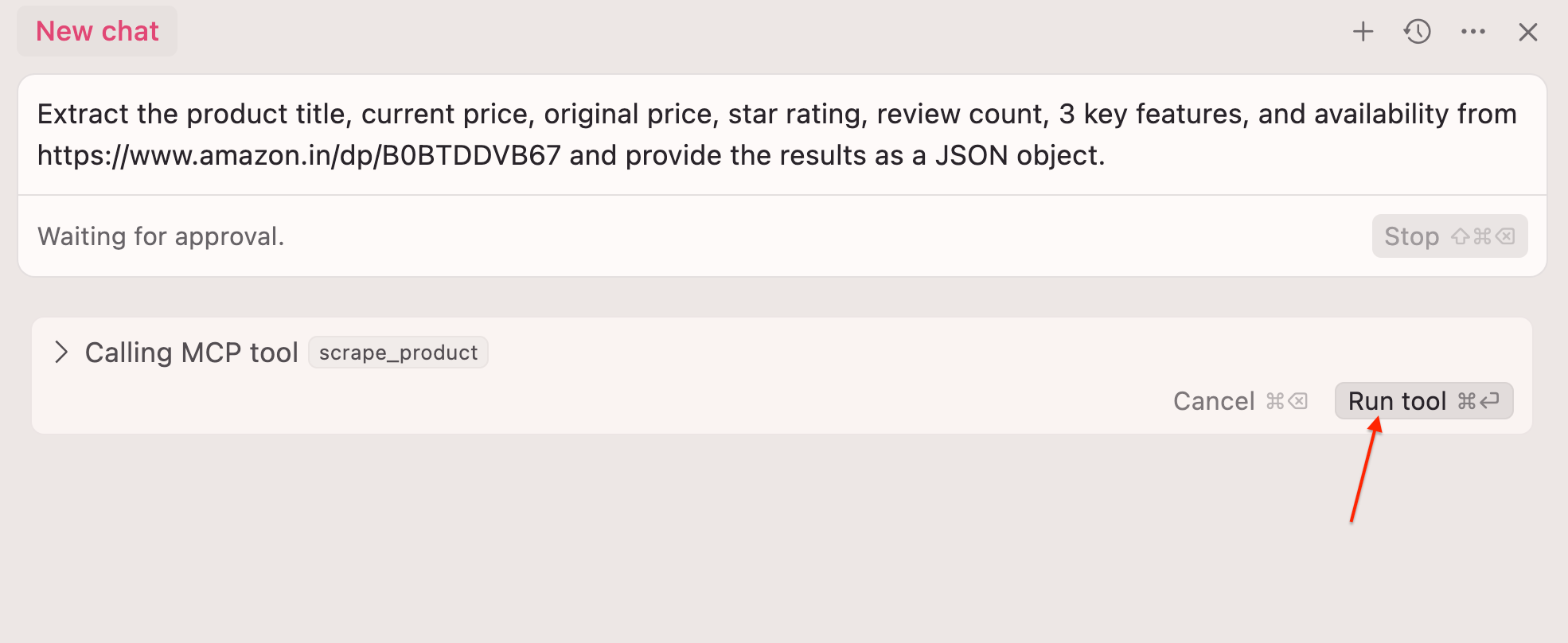
cursor-chat-interface
Step 7: Click the Run tool ⏎
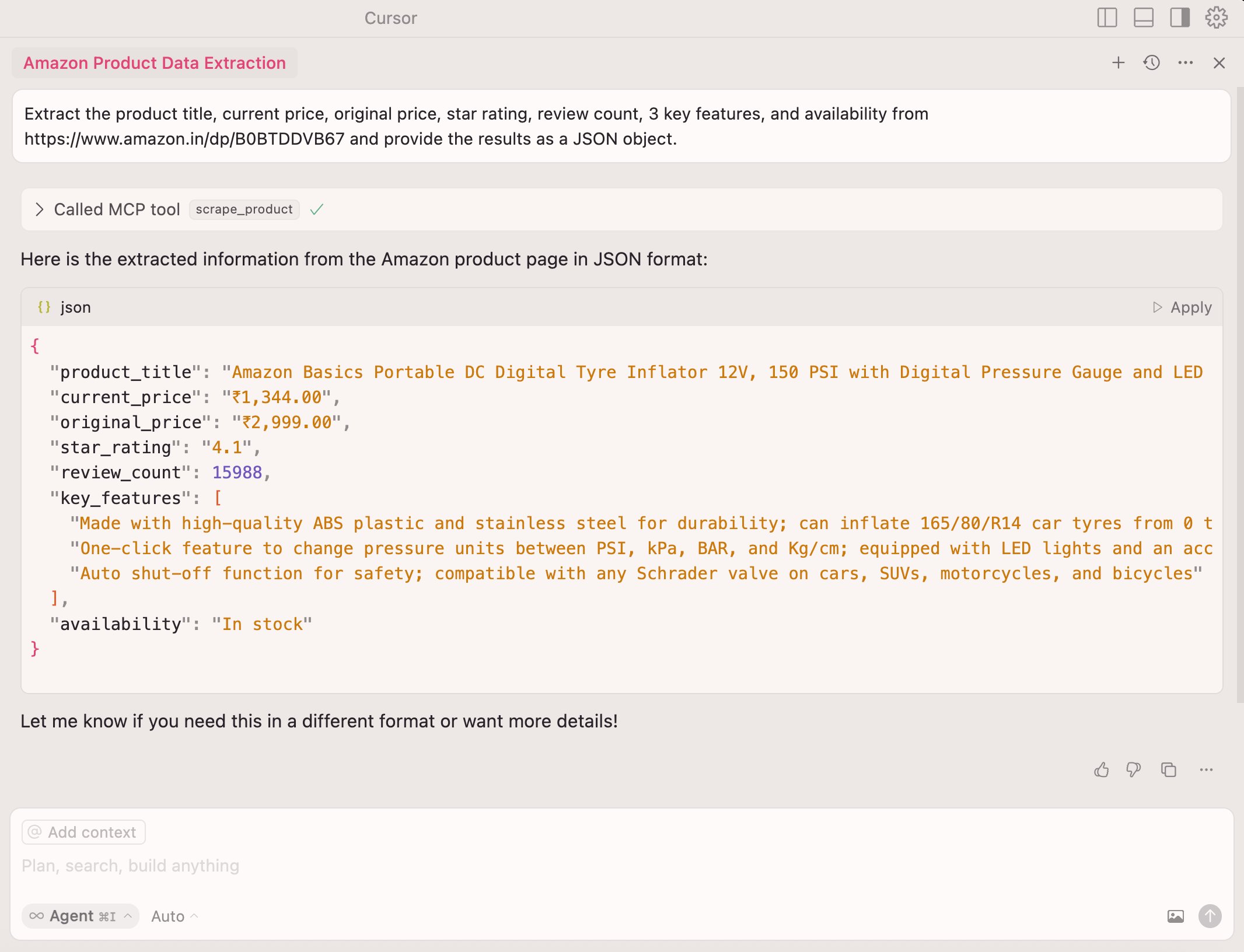
The AI handles all the extraction logic—no selectors needed!
👉 Check out how to integrate Bright Data’s MCP server to access real-time, AI-ready web data.
When to Use Each Approach
After building both scrapers, the trade-offs become clear.
Choose traditional scraping when you need end-to-end control over every request, selector, and proxy.
High-volume, repeatable jobs
Well-defined sites that rarely change
Pipelines where every millisecond and dependency count
💡 Tip: For Traditional Scraping:
Explore Bright Data’s proxy services to handle IP rotation and geographic restrictions
Try Web Scraper APIs for pre-built extraction from 120+ popular domains
Browse the Dataset Marketplace for ready-to-use data
On the other hand, adopt MCP-driven workflows when your product is already LLM-centric or you want agents to fetch live data on demand.
Rapid prototypes, where writing selectors slows you down
Sites that change frequently or vary across domains
Less technical teammates can trigger data collection using prompts
Complex flows (e.g., search → paginate → extract) that benefit from LLM reasoning
Conversational apps that can tolerate extra latency or tool-call cost
💡 Tip: For MCP Integration:
Check out the community MCP servers
Experiment with the official MCP reference implementations
Test Bright Data’s MCP integration for enterprise-grade reliability.
Bright Data’s MCP server
wraps
Web Unlocker
,
Crawl API
,
Browser API
, or
SERP API
behind a single JSON-RPC endpoint. Your agent simply calls
available tools
such as
search_engine
, and the server handles stealth browsing, CAPTCHA solving, and proxy rotation automatically.
The Future Is Hybrid
Neither approach is a silver bullet, so smart teams combine both.
Use MCP for discovery. Spin up prompt-driven scrapers to validate new data sources in minutes.
Optimize with traditional code. Once the target and schema are stable, switch to hand-tuned selectors for speed and cost efficiency.
Expose mature scrapers as MCP tools. Wrap your existing Python or Node.js crawlers in a lightweight MCP server so agents can invoke them with a single function call.
Modern platforms already follow this model. For example, Bright Data’s MCP server lets you combine AI-led exploration with production-grade scraping infrastructure.
Conclusion
Traditional web scraping isn’t going anywhere – it still powers most large-scale data operations. MCP, meanwhile, brings a new layer of flexibility and LLM-ready intelligence.
The future is hybrid – use both and switch as the job demands.
If you need scalable, compliant infrastructure for AI-driven extraction, see Bright Data’s AI-Ready Web Data Infrastructure – from residential proxies to pre-built APIs and a fully managed MCP server.
Already building agent workflows? Check out the guide on integrating Google ADK with Bright Data MCP .