
How To Set Up Proxy in Rust - Full Guide
{ "@context": "https://schema.org", "@type": "HowTo", "name": "Setting Up a Proxy in Rust: A Complete Guide", "description": "This comprehensive guide teaches you how to set up and manage proxies in Rust applications, enabling you to navigate web scraping challenges, circumvent geoblocks, avoid IP bans, and maintain anonymity. It covers the essentials of proxy server basics, configuring Nginx as a local proxy, and integrating proxy settings into Rust for seamless web scraping.", "step": [ { "@type": "HowToStep", "name": "Understand Proxy Server Basics", "text": "Learn the roles and benefits of using a proxy server in web scraping with Rust, including IP ban avoidance, geoblock circumvention, and anonymity." }, { "@type": "HowToStep", "name": "Set Up Nginx as a Proxy Server", "text": "Install Nginx on your local machine and configure it to act as a proxy server. Modify the nginx.conf file to forward requests and add custom headers." }, { "@type": "HowToStep", "name": "Create a Rust Web Scraping Project", "text": "Initialize a new Rust project with Cargo, add dependencies like reqwest and scraper for HTTP requests and HTML parsing, and implement the web scraping logic." }, { "@type": "HowToStep", "name": "Integrate Proxy Configuration in Rust", "text": "Update your Rust application to use the local Nginx proxy server for outgoing web requests, ensuring your web scraping activities utilize the proxy." }, { "@type": "HowToStep", "name": "Implement Rotating Proxies", "text": "Enhance your Rust application by incorporating a system to rotate through a set of proxies, distributing the load and reducing the risk of detection." }, { "@type": "HowToStep", "name": "Utilize Bright Data Proxy Service", "text": "For a more robust solution, integrate your Rust application with Bright Data's proxy services, offering access to a vast network of proxies worldwide." }, { "@type": "HowToStep", "name": "Test and Verify Proxy Integration", "text": "Confirm the successful integration of proxy settings in your Rust application by making requests to an API that reveals the client's IP address, ensuring the proxy is being used." } ], "estimatedCost": { "@type": "MonetaryAmount", "currency": "USD", "value": "Varies" }, "supply": [ { "@type": "HowToSupply", "name": "Rust development environment", "requiredQuantity": 1 }, { "@type": "HowToSupply", "name": "Nginx server for proxy setup", "requiredQuantity": 1 }, { "@type": "HowToSupply", "name": "Bright Data proxy service subscription (optional)", "requiredQuantity": 1 } ], "tool": [ { "@type": "HowToTool", "name": "Cargo (Rust's package manager)" }, { "@type": "HowToTool", "name": "reqwest and scraper crates for Rust" }, { "@type": "HowToTool", "name": "Nginx configuration file" } ] }
If you’ve been web scraping for any amount of time, you may have encountered a blocked website behind a geofence or an IP ban. Proxy servers help you navigate these situations, masking your true identity and granting access to forbidden resources.
Rust proxy servers make it easy to do the following:
Avoid IP bans: A fresh proxy IP lets you bypass the banhammer and resume scraping.
Circumvent geoblocks: If you’re interested in content from another country, a local proxy grants you temporary online citizenship, making restricted content accessible.
Embrace anonymity: A proxy server hides your real IP address, protecting your privacy from prying eyes.
And that’s just the tip of the iceberg! Rust’s powerful libraries and robust syntax make setting up and managing proxies a breeze. In this article, you’ll learn all about proxy servers and how to use a proxy server in Rust for web scraping.
Using a Proxy Server in Rust
Before you can use a proxy server in Rust, you need to set one up. In this tutorial, you’ll set up a proxy in an Nginx server on your local machine and use it to send scraping requests to a scraping sandbox (such as https://toscrape.com/ ) from a Rust binary.
Start by installing Nginx on your local system. For Linux, you can install it using Homebrew with the following command:
sudo apt install nginxThen start the server with the following command:
nginx
Next, you need to configure the server to act as a proxy for certain locations. For instance, you could configure it to function as a proxy for the location
/
and add a header (
ie
X-Proxy-Server
) to each request that it handles. To do that, you need to edit the
nginx.conf
file.
The file location differs based on your host operating system. Refer to the
Nginx docs
for assistance. On a Linux, you can find
nginx.conf
at
/etc/nginx/nginx.conf
. Open it and add the following code block to the
http.server
object in the file:
http {
server {
# Add the following block
location / {
resolver 8.8.8.8;
proxy_pass http://$http_host$request_uri;
proxy_set_header 'X-Proxy-Server' 'Nginx';
}
}
}
This configures the proxy to forward all incoming requests to the original URL while adding a header to the request. If you had access to the logs on the target server, you could check for this header to verify if the request came through the proxy or from the client directly.
Now, run the following command to restart the Nginx server:
nginx -s reload
This server is now ready to be used as a forward proxy for scraping.
Creating a Web Scraping Project in Rust
To set up a new scraping project, create a new Rust binary using Cargo by running the following command:
cargo new rust-scraper
Once the project is created, you need to add three crates. To start, you add
reqwest
and
scraper
. You use
reqwest
to send requests to the target resource and
scraper
to extract the required data from the HTML received by
reqwest
. Then you add your third crate,
tokio
, to handle asynchronous network calls through
reqwest
.
To install these, run the following command inside the project directory:
cargo add scraper reqwest tokio --features "reqwest/blocking tokio/full"
Next, open the
src/main.rs
file and add the following code:
use reqwest;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>>{
let url = "http://books.toscrape.com/";
let client = reqwest::Client::new();
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
extract_products(&html_content);
Ok(())
}
fn extract_products(html_content: &str) {
let document = scraper::Html::parse_document(&html_content);
let html_product_selector = scraper::Selector::parse("article.product_pod").unwrap();
let html_products = document.select(&html_product_selector);
let mut products: Vec<Product> = Vec::new();
for html_product in html_products {
let url = html_product
.select(&scraper::Selector::parse("a").unwrap())
.next()
.and_then(|a| a.value().attr("href"))
.map(str::to_owned);
let image = html_product
.select(&scraper::Selector::parse("img").unwrap())
.next()
.and_then(|img| img.value().attr("src"))
.map(str::to_owned);
let name = html_product
.select(&scraper::Selector::parse("h3").unwrap())
.next()
.map(|title| title.text().collect::<String>());
let price = html_product
.select(&scraper::Selector::parse(".price_color").unwrap())
.next()
.map(|price| price.text().collect::<String>());
let product = Product {
url,
image,
name,
price,
};
products.push(product);
}
println!("{:?}", products);
}
#[derive(Debug)]
struct Product {
url: Option<String>,
image: Option<String>,
name: Option<String>,
price: Option<String>,
}
This code uses the
reqwest
crate to create a client and get the web page at the URL
https://books.toscrape.com
. Then it processes the HTML of the page inside a function titled
extract_products
to extract a list of products from the page. The extraction logic is implemented using the
scraper
crate and remains unchanged whether or not you use a proxy.
Now, it’s time to try running this binary to see if it extracts the list of products correctly. To do that, run the following command:
cargo run
You should see an output that looks like this in your terminal:
Finished dev [unoptimized + debuginfo] target(s) in 0.80s
Running `target/debug/rust_scraper`
[Product { url: Some("catalogue/a-light-in-the-attic_1000/index.html"), image: Some("media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg"), name: Some("A Light in the ..."), price: Some("£51.77") }, Product { url: Some("catalogue/tipping-the-velvet_999/index.html"), image: Some("media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg"), name: Some("Tipping the Velvet"), price: Some("£53.74") }, Product { url: Some("catalogue/soumission_998/index.html"), image: Some("media/cache/3e/ef/3eef99c9d9adef34639f510662022830.jpg"), name: Some("Soumission"), price: Some("£50.10") }, Product { url: Some("catalogue/sharp-objects_997/index.html"), image: Some("media/cache/32/51/3251cf3a3412f53f339e42cac2134093.jpg"), name: Some("Sharp Objects"), price: Some("£47.82") }, Product { url: Some("catalogue/sapiens-a-brief-history-of-humankind_996/index.html"), image: Some("media/cache/be/a5/bea5697f2534a2f86a3ef27b5a8c12a6.jpg"), name: Some("Sapiens: A Brief History ..."), price: Some("£54.23") }, Product { url: Some("catalogue/the-requiem-red_995/index.html"), image: Some("media/cache/68/33/68339b4c9bc034267e1da611ab3b34f8.jpg"), name: Some("The Requiem Red"), price: Some("£22.65") }, Product { url: Some("catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"), image: Some("media/cache/92/27/92274a95b7c251fea59a2b8a78275ab4.jpg"), name: Some("The Dirty Little Secrets ..."), price: Some("£33.34") }, Product { url: Some("catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html"), image: Some("media/cache/3d/54/3d54940e57e662c4dd1f3ff00c78cc64.jpg"), name: Some("The Coming Woman: A ..."), price: Some("£17.93") }, Product { url: Some("catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html"), image: Some("media/cache/66/88/66883b91f6804b2323c8369331cb7dd1.jpg"), name: Some("The Boys in the ..."), price: Some("£22.60") }, Product { url: Some("catalogue/the-black-maria_991/index.html"), image: Some("media/cache/58/46/5846057e28022268153beff6d352b06c.jpg"), name: Some("The Black Maria"), price: Some("£52.15") }, Product { url: Some("catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html"), image: Some("media/cache/be/f4/bef44da28c98f905a3ebec0b87be8530.jpg"), name: Some("Starving Hearts (Triangular Trade ..."), price: Some("£13.99") }, Product { url: Some("catalogue/shakespeares-sonnets_989/index.html"), image: Some("media/cache/10/48/1048f63d3b5061cd2f424d20b3f9b666.jpg"), name: Some("Shakespeare's Sonnets"), price: Some("£20.66") }, Product { url: Some("catalogue/set-me-free_988/index.html"), image: Some("media/cache/5b/88/5b88c52633f53cacf162c15f4f823153.jpg"), name: Some("Set Me Free"), price: Some("£17.46") }, Product { url: Some("catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html"), image: Some("media/cache/94/b1/94b1b8b244bce9677c2f29ccc890d4d2.jpg"), name: Some("Scott Pilgrim's Precious Little ..."), price: Some("£52.29") }, Product { url: Some("catalogue/rip-it-up-and-start-again_986/index.html"), image: Some("media/cache/81/c4/81c4a973364e17d01f217e1188253d5e.jpg"), name: Some("Rip it Up and ..."), price: Some("£35.02") }, Product { url: Some("catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html"), image: Some("media/cache/54/60/54607fe8945897cdcced0044103b10b6.jpg"), name: Some("Our Band Could Be ..."), price: Some("£57.25") }, Product { url: Some("catalogue/olio_984/index.html"), image: Some("media/cache/55/33/553310a7162dfbc2c6d19a84da0df9e1.jpg"), name: Some("Olio"), price: Some("£23.88") }, Product { url: Some("catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html"), image: Some("media/cache/09/a3/09a3aef48557576e1a85ba7efea8ecb7.jpg"), name: Some("Mesaerion: The Best Science ..."), price: Some("£37.59") }, Product { url: Some("catalogue/libertarianism-for-beginners_982/index.html"), image: Some("media/cache/0b/bc/0bbcd0a6f4bcd81ccb1049a52736406e.jpg"), name: Some("Libertarianism for Beginners"), price: Some("£51.33") }, Product { url: Some("catalogue/its-only-the-himalayas_981/index.html"), image: Some("media/cache/27/a5/27a53d0bb95bdd88288eaf66c9230d7e.jpg"), name: Some("It's Only the Himalayas"), price: Some("£45.17") }]
This means that the scraping logic works correctly. Now, you’re ready to add your Nginx proxy to this scraper.
Making Use of Your Proxy
You’ll notice that the scraping request is sent through a full-fledged
reqwest
client in the
main()
function (instead of using a one-off
get
call). This means you can easily configure a proxy when creating the client.
To configure the client, update the following line of code:
async fn main() -> Result<(), Box<dyn Error>>{
let url = "https://books.toscrape.com/";
# Replace this line
let client = reqwest::Client::new();
# With this one
let client = reqwest::Client::builder()
.proxy(reqwest::Proxy::https("http://localhost:8080")?)
.build()?;
//...
Ok(())
}
When configuring the proxy using
reqwest
, it’s important to understand that some proxy providers (including Bright Data) work with both
http
and
https
configurations but might require some extra configuration. If you face issues when using
https
, try switching to
http
to run the app.
When configuring the proxy using
reqwest
, it’s important to understand that some proxy providers (including Bright Data) work with both
http
and
https
configurations but might require some extra configuration. If you face issues when using
https
, try switching to
http
to run the app.
Now, try running the binary again using the
cargo run
command. You should receive a similar response as before. However, make sure you look into your Nginx server’s logs to see if a request was proxied through it.
Locate your
Nginx server’s logs
based on the instructions for your operating system. For a Homebrew-based installation on Mac, the access and error log files are in the
/opt/homebrew/var/log/nginx
folder. Open the
access.log
file, and you should see a line like this at the bottom of the file:
127.0.0.1 - - [07/Jan/2024:05:19:54 +0530] "GET https://books.toscrape.com/ HTTP/1.1" 200 18 "-" "-"
This indicates that the request was proxied through the Nginx server. Now, you can set up the server on a remote host so that you can make use of it to circumvent georestrictions or IP blocks.
Rotating Proxies
When working on web scraping projects, you might need to rotate between a set of proxies. This allows you to spread your scraping workload between multiple IPs and avoid getting detected due to high traffic from a single source or location.
To implement rotating proxies, you need to add the following functions to your
main.rs
file:
#[derive(Debug)]
struct Proxy {
ip: String,
port: String,
}
fn get_proxies() -> Vec<Proxy> {
let mut proxies = Vec::new();
proxies.push(Proxy {
ip: "http://localhost".to_string(),
port: "8082".to_string(),
});
// Add more proxies.push statements here to create a bigger set of proxies
proxies
}
This helps you define the set of proxies easily. Then you need to update the
main
function like this to make use of a randomized proxy:
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let url = "https://books.toscrape.com/";
// Add these two lines
let proxies = get_proxies();
let random_proxy = proxies.choose(&mut rand::thread_rng()).unwrap();
let client = reqwest::Client::builder()
// Update the following line to match this
.proxy(reqwest::Proxy::http(format!("{0}:{1}", random_proxy.ip, random_proxy.port))?)
.build()?;
// Rest remains the same
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
extract_products(&html_content);
Ok(())
}
Now, you need to install the
rand
crate to be able to randomize picking a proxy from the array of proxies. You can do that by running the following command:
cargo add rand
Then add the following line at the top of your
main.rs
file to import the
rand
crate:
use rand::seq::SliceRandom;
Now, try running the binary again to see if it works using the
cargo run
command. It should print the same output as before, indicating that the randomized proxy list is set up correctly.
Bright Data Proxy Server
As you’ve seen, manually setting up a proxy can be a lot of work. Additionally, you need to host the proxy server on a remote server to be able to make use of all the benefits of a new IP address and location. If you want to avoid all that hassle, consider using one of the Bright Data proxy servers .
While countless proxy providers exist, Bright Data is known for its sheer scale and flexibility. With Bright Data, you get a sprawling network of 150 million+ residential, mobile, data center, and ISP proxies scattered across 195 countries. With its large number of residential proxies, you can target specific countries, cities, or even mobile carriers for laser-focused scraping.
Additionally, Bright Data residential proxies blend seamlessly with real user traffic, while the data center and mobile options provide blazing speed and reliable connections. The Bright Data automatic rotation keeps your scraping nimble, minimizing the risk of detection and ban hammers.
To try it out for yourself, head over to https://brightdata.com/ and click on Start Free Trial in the top-right corner. Once you’ve signed up, you’ll be taken to the Control Panel page:
On this page, click on View proxy products to navigate to the Proxies & Scraping Infrastructure page:
This page lists all the proxies that you’ve previously provisioned. To add a proxy, click on the blue Add button on the top-right and choose Residential Proxies :
A form then pops up where you can configure your new residential proxy. Leave the default options, scroll to the bottom of the page, and click Add .
Once the residential proxy is created, you’ll be navigated to a page that shows the details of the newly created proxy. Click on the Access parameters tab to view the proxy’s host, username, and password:
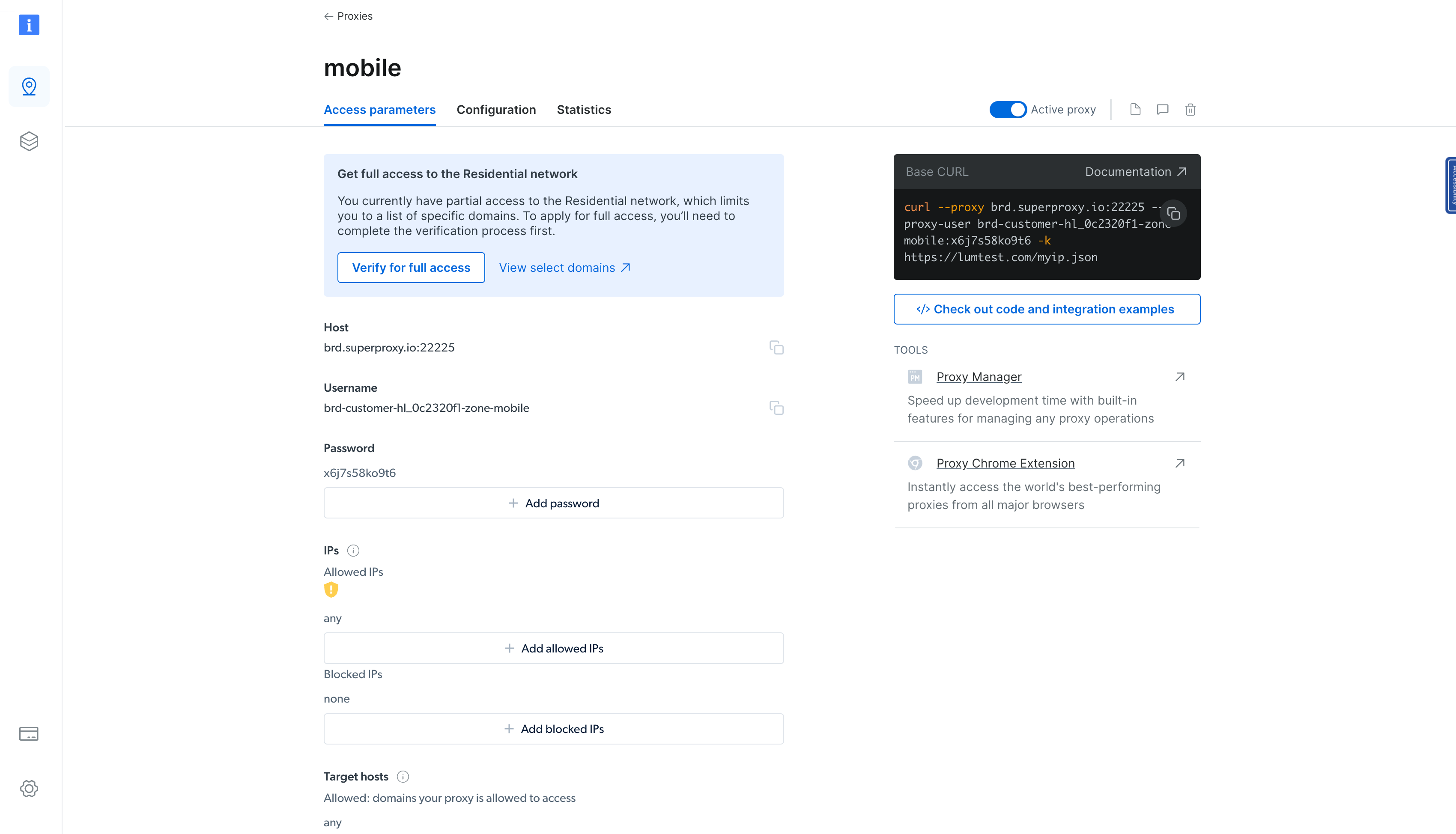
You can use these parameters to integrate the proxy in your Rust binary. To do that, update the
main()
function in the
src/main.rs
file like this:
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let url = "https://books.toscrape.com/";
// Update the following block with the details from the Bright Data proxy details page
let client = reqwest::Client::builder()
.proxy(reqwest::Proxy::http("<BD proxy hostname & port>")?
.basic_auth("<your BD username>", "<your BD password>"))
.build()?;
// Rest remains the same
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
extract_products(&html_content);
Ok(())
}
Then try running the binary again. It should return the response correctly as before. The only key difference here is that the request is being proxied through Bright Data, hiding your identity and real location.
You can confirm this by sending a request to an API that displays the IP address of the client using the following code snippet:
use reqwest;
use std::error::Error;
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let url = "http://lumtest.com/myip.json";
// Update the following block with the details from the Bright Data proxy details page
let client = reqwest::Client::builder()
.proxy(reqwest::Proxy::http("<BD proxy hostname & port>")?
.basic_auth("<your BD username>", "<your BD password>"))
.build()?;
// Rest remains the same
let response = client
.get(url)
.send()
.await?;
let html_content = response.text().await?;
println!("{:?}", html_content);
Ok(())
}
When you run the code using the
cargo run
command, you should see an output that looks like this:
"{"ip":"209.169.64.172","country":"US","asn":{"asnum":6300,"org_name":"CCI-TEXAS"},"geo":{"city":"Conroe","region":"TX","region_name":"Texas","postal_code":"77304","latitude":30.3228,"longitude":-95.5298,"tz":"America/Chicago","lum_city":"conroe","lum_region":"tx"}}"
This will reflect the IP and the location details of the proxy server you’re using to query the page.
Conclusion
In this article, you learned how to use proxies with Rust. Remember, proxies are like digital masks, letting you get past online restrictions and peek behind websites’ restrictions. They also allow you to maintain your anonymity when navigating the web.
However, setting up a proxy on your own is a complex process. It’s usually recommended that you go with an established proxy provider such as Bright Data , which offers a pool of 150 million+ easy-to-use proxies.
GitHub repository