
How to Scrape Craigslist With Python: Step-By-Step Guide
For 30 years, Craigslist has been a go-to marketplace for all kinds of deals. In spite of its very simple, 1990s design, Craigslist might be the best place in the world to shop “for sale by owner” deals.
Today, we’re going to extract car data from Craigslist using a Python scraper . Follow along and you’ll be scraping Craigslist like a pro in no time.
What to Extract From Craigslist
Digging Through HTML: The Hard Way
The most important skill in web scraping is knowing where to look. We could write an overcomplicated parser that pulls individual items from the HTML code .
If you look at the truck in the image below, its data is nested within a
div
element of the class
cl-gallery
. If we want to do things the hard way, we can find this tag and then further parse elements from there.
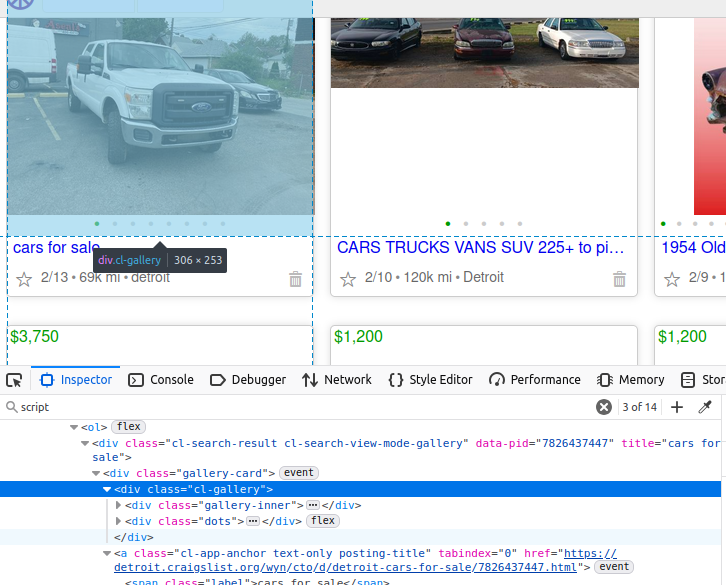
Inspecting the HTML
Finding The JSON: Saving Precious Time
However, there’s a better way. Many sites, including Craigslist, use embedded JSON data to build the entire page. If you can find this JSON, it cuts your parsing work to almost zero.
On a Craigslist page, there is a
script
object holding all the data we want. If we pull this one element, we get the data from their entire page. If you look, its
id
is
ld_searchpage_results
. We can locate this element with the
CSS selector
:
script[id='ld_searchpage_results']
.
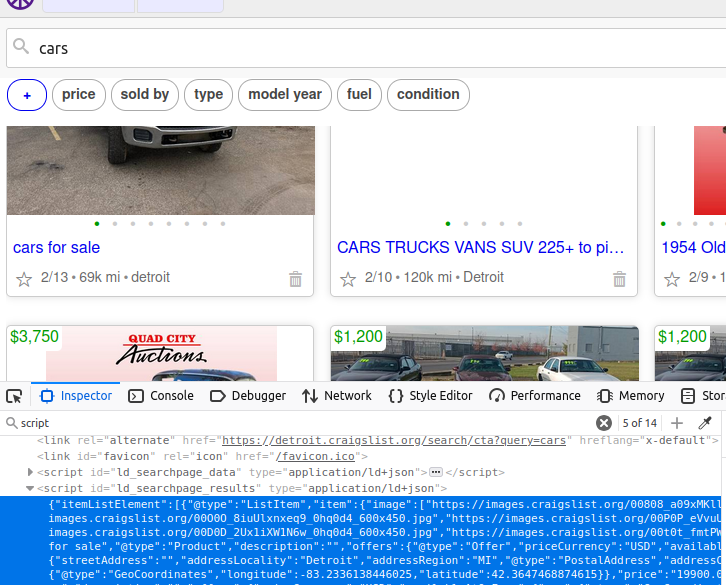
Inspect and Find the JSON
Scraping Craigslist With Python
Now that we know what we’re trying to find, scraping Craigslist is going to be much easier. In these next few sections, we’ll go over the individual code and then put it all together into a functional scraper.
Parsing the Page
def scrape_listings(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
success = False
while not success:
try:
response = requests.get(url)
#if we receive a bad status code, throw an error
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']")
json_data = json.loads(embedded_json_string.text).get("itemListElement")
for dirty_item in json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
if len(images) > 0:
image = images[0]
clean_item = {
"name": item.get("name"),
"image": image,
"price": item.get("offers").get("price"),
"currency": item.get("offers").get("priceCurrency"),
"city": location_info.get("address").get("addressLocality"),
"region": location_info.get("address").get("addressRegion"),
"country": location_info.get("address").get("addressCountry")
}
scraped_data.append(clean_item)
#we made it through all the listings, set success = True and break the loop
success = True
except Exception as e:
print(f"Failed to scrape the listings, {e} at {url}")
return scraped_data
First, we create our
url
,
scraped_data
and
success
variables.
url
: The exact url of the search we want to perform.
scraped_data
: This is where we put all of our search results.
success
: We want this scraper to be persistent. Used in combination with a
while
loop, our scraper won’t exit until the job has completed and we set success to
True
.
Then, we get the page and throw an error in the event of a bad response.
soup = BeautifulSoup(response.text, "html.parser")
creates a
BeautifulSoup
object that we can use to parse the page.
We find our embedded JSON with
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']")
.
We then convert it into a
dict
with
json.loads()
.
Next, we iterate through all the items and clean their data. The
clean_item
gets appended to our
scraped_data
.
Finally, we set
success
to
True
and return the array of scraped listings.
url
: The exact url of the search we want to perform.
scraped_data
: This is where we put all of our search results.
success
: We want this scraper to be persistent. Used in combination with a
while
loop, our scraper won’t exit until the job has completed and we set success to
True
.
Storing Our Data
The two most common storage methods in web scraping are CSV and JSON . We’ll walk through how to store our listings in both formats.
Saving to a JSON File
This basic snippet contains our JSON storage logic. We open a file and pass it into
json.dump()
along with our data. We use
indent=4
to make the JSON file readable.
with open(f"{QUERY}-{LOCATION}.json", "w") as file:
try:
json.dump(listings, file, indent=4)
except Exception as e:
print(f"Failed to save the results: {e}")
Saving to a CSV File
Saving to a CSV requires a little more work. CSV doesn’t handle arrays very well. This is why we only extracted one image when cleaning the data.
If there are no listings, the function exits. If there are listings, we write the CSV headers using the
keys()
from the first item in the array. Then we use
csv.DictWriter()
to write the headers and the
listings
.
def write_listings_to_csv(listings, filename):
if not listings:
print("No listings found. Skipping CSV writing.")
return
# Define CSV column headers
fieldnames = listings[0].keys()
# Write data to CSV
with open(filename, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(listings)
Putting it All Together
Now, we can put all these pieces together. This code contains our fully functional scraper.
import requests
from bs4 import BeautifulSoup
import json
import csv
def write_listings_to_csv(listings, filename):
if not listings:
print("No listings found. Skipping CSV writing.")
return
# Define CSV column headers
fieldnames = listings[0].keys()
# Write data to CSV
with open(filename, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(listings)
def scrape_listings(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
success = False
while not success:
try:
response = requests.get(url)
#if we receive a bad status code, throw an error
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']")
json_data = json.loads(embedded_json_string.text).get("itemListElement")
for dirty_item in json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
if len(images) > 0:
image = images[0]
clean_item = {
"name": item.get("name"),
"image": image,
"price": item.get("offers").get("price"),
"currency": item.get("offers").get("priceCurrency"),
"city": location_info.get("address").get("addressLocality"),
"region": location_info.get("address").get("addressRegion"),
"country": location_info.get("address").get("addressCountry")
}
scraped_data.append(clean_item)
#we made it through all the listings, set success = True and break the loop
success = True
except Exception as e:
print(f"Failed to scrape the listings, {e} at {url}")
return scraped_data
if __name__ == "__main__":
LOCATION = "detroit"
QUERY = "cars"
OUTPUT = "csv"
listings = scrape_listings(LOCATION, QUERY)
if OUTPUT == "json":
with open(f"{QUERY}-{LOCATION}.json", "w") as file:
try:
json.dump(listings, file, indent=4)
except Exception as e:
print(f"Failed to save the results: {e}")
elif OUTPUT == "csv":
try:
write_listings_to_csv(listings, f"{QUERY}-{LOCATION}.csv")
print(f"Saved {len(listings)} listings to {QUERY}-{LOCATION}.csv")
except Exception as e:
print(f"Failed to write CSV output: {e}")
else:
print("Output method not supported")
Inside the
main
block, you can handle storage methods with the
OUTPUT
variable. If you want to store in a JSON file, set it to
json
. If you want a CSV, set this variable to
csv
. In data collection, you’re going to use both of these storage methods all the time.
JSON Output
As you can see in the image below, each car is represented by a readable JSON object with a clean, clear structure.
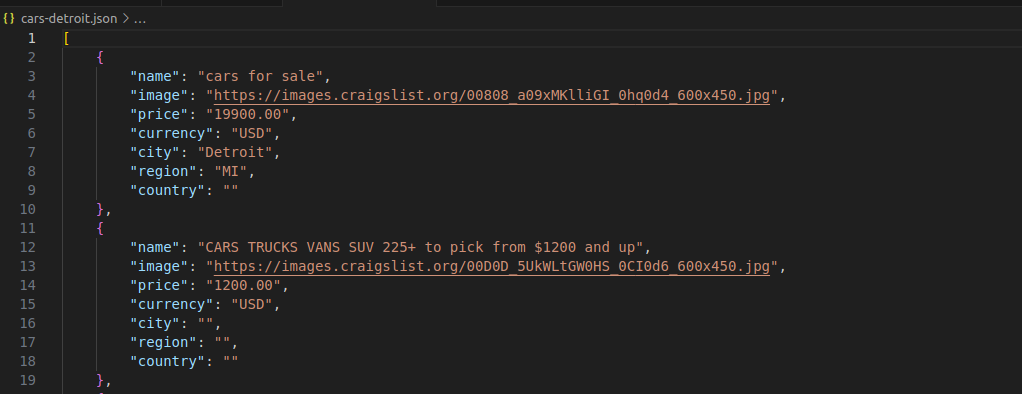
JSON Output
CSV Output
Our CSV output is pretty similar. We get a clean spreadsheet holding all of our listings.
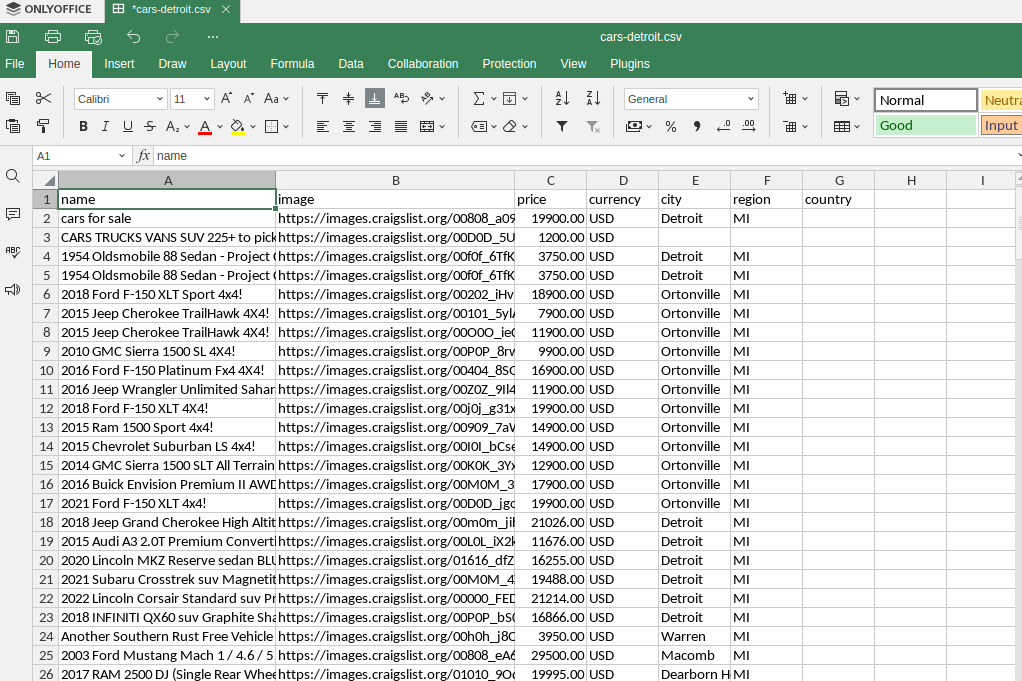
CSV output
Using Scraping Browser
Scraping Browser allows us to run a Playwright instance with proxy integration. This can take your scraping to the next level by operating a full browser from your Python script. If you are interested in integrating proxies with Playwright
In the code below, our parsing method remains largely the same, but we use
asyncio
with
async_playwright
to open a
headless browser
and actually fetch the page using this browser. Instead of
BeautifulSoup
, we pass our CSS selector into Playwright’s
query_selector()
method.
import asyncio
from playwright.async_api import async_playwright
import json
AUTH = 'brd-customer-<YOUR-USERNAME>-zone-<YOUR-ZONE-NAME>:<YOUR-PASSWORD>'
SBR_WS_CDP = f'wss://{AUTH}@brd.superproxy.io:9222'
async def scrape_listings(keyword, location):
print('Connecting to Scraping Browser...')
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
async with async_playwright() as p:
browser = await p.chromium.connect_over_cdp(SBR_WS_CDP)
context = await browser.new_context()
page = await context.new_page()
try:
print('Connected! Navigating to webpage...')
await page.goto(url)
embedded_json_string = await page.query_selector("script[id='ld_searchpage_results']")
json_data = json.loads(await embedded_json_string.text_content())["itemListElement"]
for dirty_item in json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
if len(images) > 0:
image = images[0]
clean_item = {
"name": item.get("name"),
"image": image,
"price": item.get("offers").get("price"),
"currency": item.get("offers").get("priceCurrency"),
"city": location_info.get("address").get("addressLocality"),
"region": location_info.get("address").get("addressRegion"),
"country": location_info.get("address").get("addressCountry")
}
scraped_data.append(clean_item)
except Exception as e:
print(f"Failed to scrape data: {e}")
finally:
await browser.close()
return scraped_data
async def main():
QUERY = "cars"
LOCATION = "detroit"
listings = await scrape_listings(QUERY, LOCATION)
try:
with open(f"{QUERY}-scraping-browser.json", "w") as file:
json.dump(listings, file, indent=4)
except Exception as e:
print(f"Failed to save results {e}")
if __name__ == '__main__':
asyncio.run(main())
Using a Custom Built No-Code Scraper
Here at Bright Data, we also offer a No-Code Craigslist Scraper . With No-Code scraper, you specify the data and pages you want to scrape. Then, we create and deploy a scraper for you!
In the “My Scrapers” section, click “New” and select “Request a custom built scraper.”
Request custom scraper
Next, you’ll be prompted to enter some URLs containing your site’s layout. In the image below, we pass the URL for our car search in Detroit. You could add a second URL for your city.
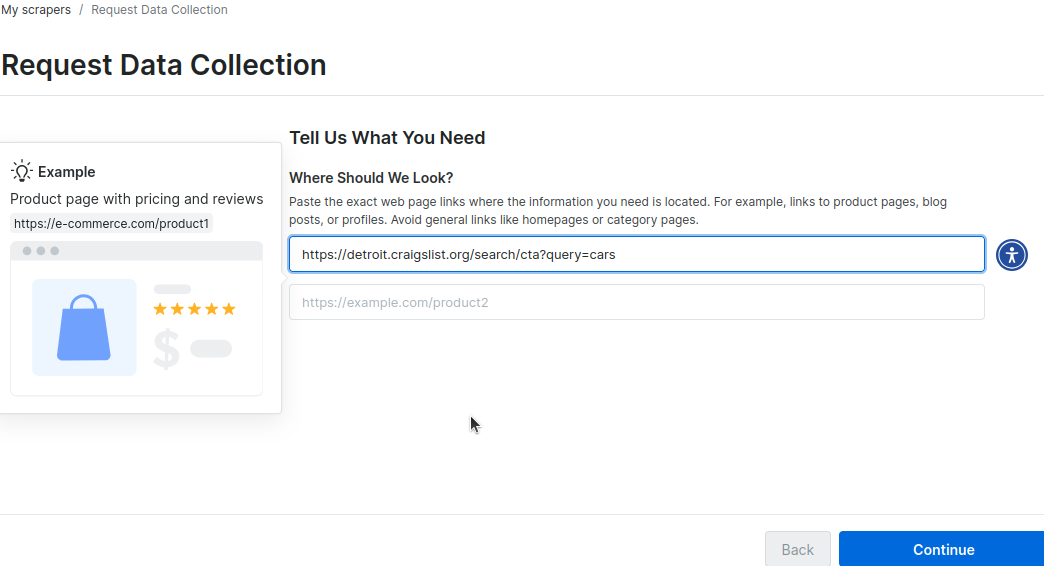
Adding the URL
Through our automated process, we scrape the sites and create a schema for you to review.
Building schema
Once the schema’s been created, you need to review it.
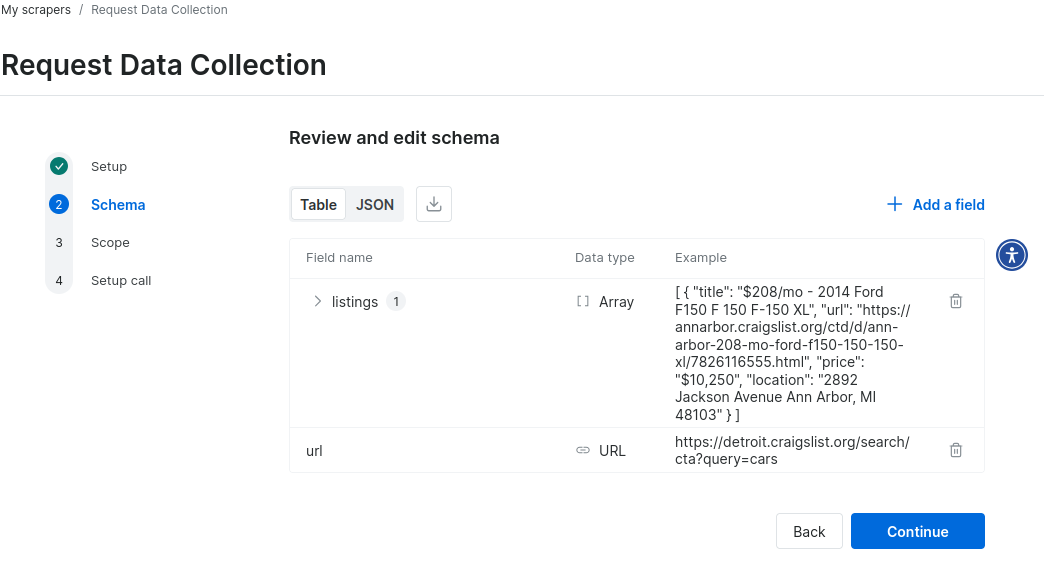
Review schema
Here’s the sample JSON data from the schema for a custom Craigslist scraper. Within minutes, there is a functional prototype.
{
"type": "object",
"fields": {
"listings": {
"type": "array",
"active": true,
"items": {
"type": "object",
"fields": {
"title": {
"type": "text",
"active": true,
"sample_value": "$208/mo - 2014 Ford F150 F 150 F-150 XL"
},
"url": {
"type": "url",
"active": true,
"sample_value": "https://annarbor.craigslist.org/ctd/d/ann-arbor-208-mo-ford-f150-150-150-xl/7826116555.html"
},
"price": {
"type": "price",
"active": true,
"sample_value": "$10,250"
},
"location": {
"type": "text",
"active": true,
"sample_value": "2892 Jackson Avenue Ann Arbor, MI 48103"
}
}
}
},
"url": {
"type": "url",
"required": true,
"active": true,
"sample_value": "https://detroit.craigslist.org/search/cta?query=cars"
}
}
}
Next, you set the collection scope. We don’t need it to scrape all of Craigslist, or just a specfic section, so we’ll feed it urls to initiate a scrape.
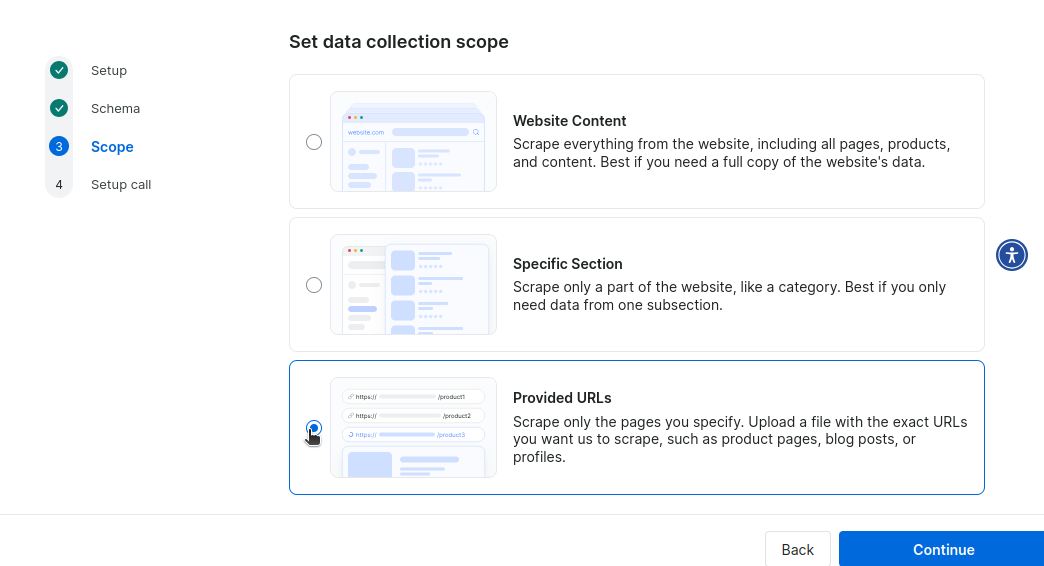
Set Collection Scope
Finally, you’ll be prompted to schedule a call with one of our experts for deployment. You can pay $300 monthly for upkeep and maintenance, or a one-time deployment fee of $1,000.
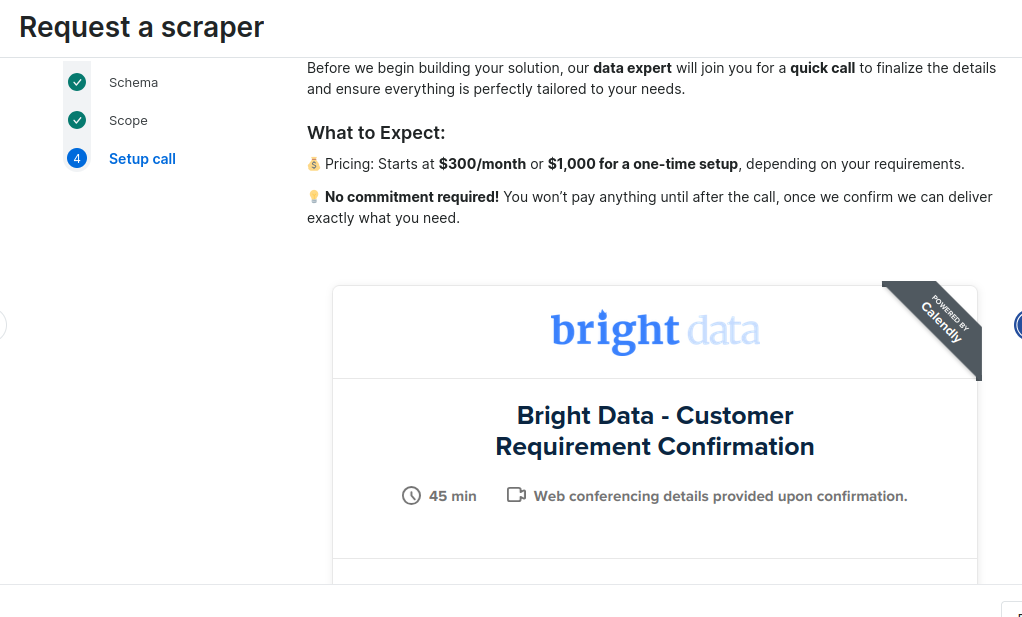
Schedule Deployment
Conclusion
When you scrape Craigslist, you can now harness Python for quick and efficient data processing. You know how to parse and clean the data. You also learned how to store it using CSV and JSON. If you need full browser functionality, you can utilize Scraping Browser to fill these needs with full proxy integration. If you’re looking to completely automate your scraping process, you now know how to handle our No-Code Scraper as well.
In addition, if you want to skip the scraping process entirely, Bright Data offers ready-to-use Craigslist datasets . Sign up now and start your free trial today!