
How to Scrape Amazon Product Data in Python: Full Guide
Amazon is a treasure trove of data for product tracking, competitor monitoring, and consumer insights. In this tutorial, you’ll learn how to scrape Amazon using tools like BeautifulSoup , Playwright , and Bright Data’s platform to streamline the process.
Scrape Amazon Manually with Python
Before you begin, ensure you have Python and key libraries (Requests, pandas, BeautifulSoup, Playwright) installed. A basic understanding of web scraping and HTML is helpful.
Want to skip manual scraping? Start using Bright Data’s Amazon Scraper .
Prerequisites
Python : Install Python 3.7.9 or newer. If you’re new to Python, see our how to scrape with Python guide .
Project Setup :
mkdir scraping-amazon-python && cd scraping-amazon-python
Required Libraries :
Requests – Handles HTTP requests.
pandas – For data manipulation and analysis.
BeautifulSoup (BS4) – Parses HTML content.
Playwright – Automates browser-related tasks.
Install via Terminal :
pip3 install beautifulsoup4
pip3 install requests
pip3 install pandas
pip3 install playwright
playwright install
Note:
playwright install
is crucial for installing the necessary browser binaries.
Navigate Amazon’s Layout and Data Components
Once you’ve installed the necessary libraries, you need to familiarize yourself with their website structure. Amazon’s main page presents a user-friendly search bar, enabling you to explore a wide array of products, from electronics to books.
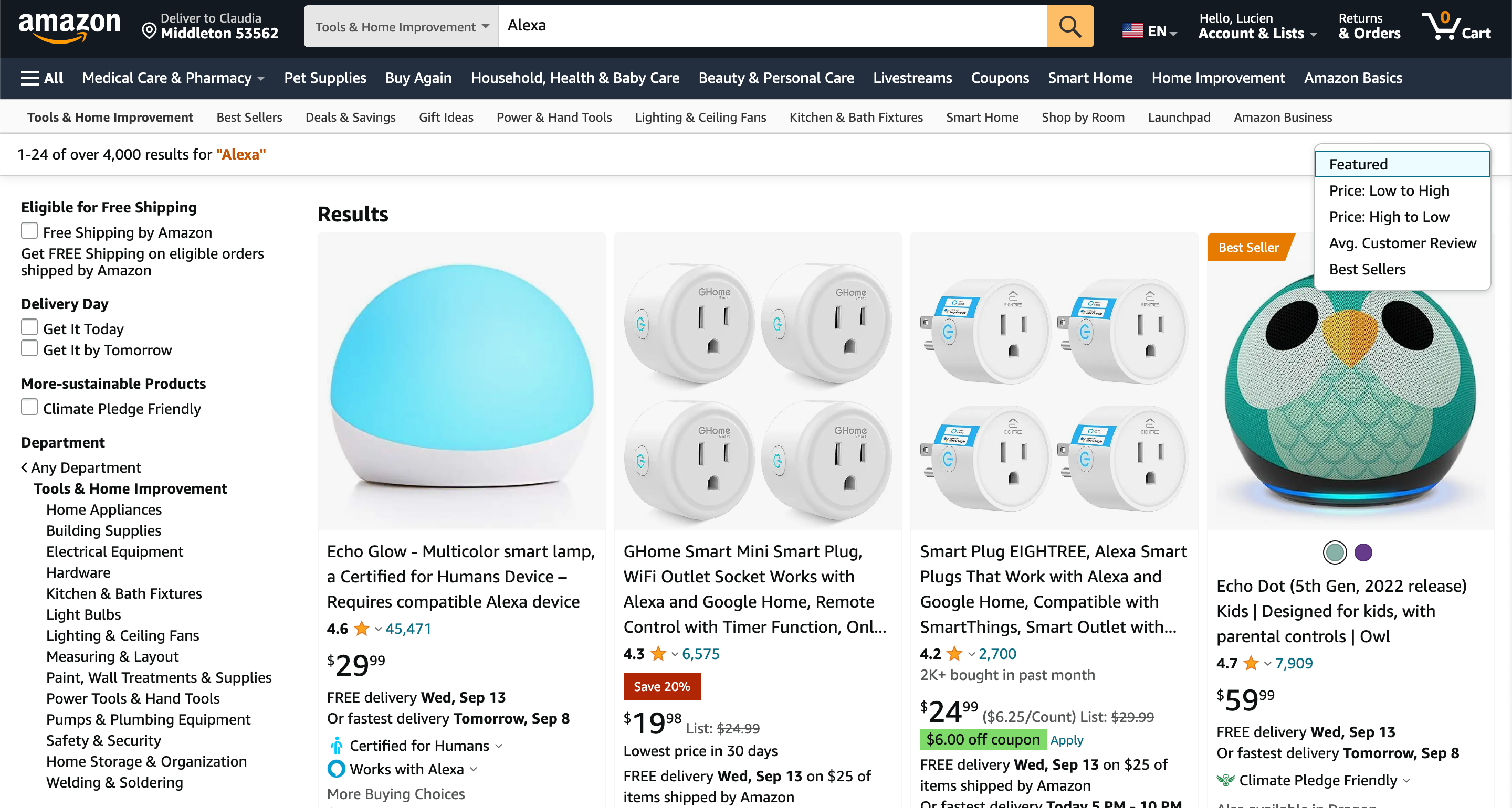
Once you input your search criteria, the outcomes are showcased in a list format, featuring products with their titles, prices, ratings, and other pertinent particulars. It’s notable that these search outcomes can be sorted using various filters, such as price range, product category, and customer reviews:
Amazon
In case you desire a more extensive list of results, you can take advantage of the pagination buttons positioned at the bottom of the page. Each page usually hosts numerous listings, giving you the opportunity to peruse additional products. The filters located at the top of the page offer a chance to refine your search according to your requirements.
To gain insight into Amazon’s HTML structure, follow these steps:
Visit the Amazon website.
Type in your desired product in the search bar or select a category from the featured list.
Open the browser’s developer tools by right-clicking on a product and selecting Inspect Element .
Explore the HTML layout to identify the tags and attributes of the data you intend to extract.
Scrape Amazon Products
Now that you’re familiar with Amazon’s product structure, in this section, you’ll gather details such as the product’s name, rating, the number of ratings, and the price.
In your project directory, create a new Python script named
amazon_scraper.py
and add the following code to it:
import asyncio
from playwright.async_api import async_playwright
import pandas as pd
async def scrape_amazon():
async with async_playwright() as pw:
# Launch new browser
browser = await pw.chromium.launch(headless=False)
page = await browser.new_page()
# Go to Amazon URL
await page.goto('https://www.amazon.com/s?i=fashion&bbn=115958409011')
# Extract information
results = []
listings = await page.query_selector_all('div.a-section.a-spacing-small')
for listing in listings:
result = {}
# Product name
name_element = await listing.query_selector('h2.a-size-mini > a > span')
result['product_name'] = await name_element.inner_text() if name_element else 'N/A'
# Rating
rating_element = await listing.query_selector('span[aria-label*="out of 5 stars"] > span.a-size-base')
result['rating'] = (await rating_element.inner_text())[0:3]await rating_element.inner_text() if rating_element else 'N/A'
# Number of reviews
reviews_element = await listing.query_selector('span[aria-label*="stars"] + span > a > span')
result['number_of_reviews'] = await reviews_element.inner_text() if reviews_element else 'N/A'
# Price
price_element = await listing.query_selector('span.a-price > span.a-offscreen')
result['price'] = await price_element.inner_text() if price_element else 'N/A'
if(result['product_name']=='N/A' and result['rating']=='N/A' and result['number_of_reviews']=='N/A' and result['price']=='N/A'):
pass
else:
results.append(result)
# Close browser
await browser.close()
return results
# Run the scraper and save results to a CSV file
results = asyncio.run(scrape_amazon())
df = pd.DataFrame(results)
df.to_csv('amazon_products_listings.csv', index=False)
In this code, you’re utilizing the asynchronous capabilities of Python with the Playwright library to scrape product listings from a specific
Amazon fashion page
. Once you launch a new browser instance and navigate to the target Amazon URL, you extract product information like the product name, rating, number of reviews, and price. After iterating over each listing on the page, you filter out listings that have no data (
ie
you mark them as “N/A”). The results of your scraping are then saved into a Pandas DataFrame and subsequently exported to a CSV file named
amazon_products_listings.csv
.
To run the script, execute
python3 amazon_scraper.py
in your terminal or shell. Your output should look like this:
product_name,rating,number_of_reviews,price
Crocs Women's Kadee Ii Sandals,4.2,17.5K+,$29.99
Teva Women's W Flatform Universal Sandal,4.7,7K+,$58.80
"OOFOS OOriginal Sport Sandal - Lightweight Recovery Footwear - Reduces Stress on Feet, Joints & Back - Machine Washable - Hand-Painted Graphics",4.5,9.4K+,N/A
"Crocs Women's Brooklyn Low Wedges, Platform Sandals",4.6,11.7K+,N/A
Teva Women's Original Universal Sandal,4.7,18.7K+,$35.37
Reef Women's Water Vista Sandal,4.5,1.9K+,$59.95
Crocs Women's Brooklyn Platform Slides Sandal,4.2,376,N/A
…output omitted…
Please note: If the script doesn’t work the first time you run it, try running it again. Amazon has sophisticated anti scrapingantiscraping measures in place that might prevent or block your data scraping attempts.
Please note: If the script doesn’t work the first time you run it, try running it again. Amazon has sophisticated anti scrapingantiscraping measures in place that might prevent or block your data scraping attempts.
Advanced Scraping Techniques for Amazon
As you start on your scraping journey with Amazon, you’ll quickly discover that this e-commerce giant, known for its complex and intricate web pages, poses challenges that require more than just basic scraping methods. Take a look at some advanced techniques that can help ensure a smooth and efficient scraping experience:
Handle Pagination
Amazon displays multiple products, often spanning several pages. To capture all data, your script should be adept at navigating through these pages seamlessly. One common method is to target the
Next
button at the bottom of product listings. By identifying its unique selector, you can program your script to
click
on this button, leading it to the next page. However, make sure your scraper waits for all elements to load before proceeding.
Bypass Advertisements
Ads often pop up in Amazon product listings. These ads might have a slightly different structure compared to regular products, potentially causing hiccups in your scraping process. To solve this, you need to detect elements or tags that signify an advertisement. For instance, look for tags with labels like
Sponsored
or
Ad
. Once detected, you can instruct your script to skip over these entries, ensuring you only gather genuine product data.
Mitigate Blocking
Amazon, being vigilant about its content, may block or temporarily suspend activities it deems robotic or suspicious. It’s crucial to make your scraper appear as humanlike as possible.
To avoid being blocked, you need to introduce delays or random intervals between requests using functions like
asyncio.sleep(random.uniform(1, 5))
. This makes your scraping pattern seem less robotic. Additionally, consider rotating user agents and IP addresses to reduce the risk of detection. Employing CAPTCHA-solving services can also be beneficial if faced with CAPTCHA challenges.
Handle Content Dynamically
Some of Amazon’s content, like reviews or Q&A sections, loads dynamically, and a basic scraper might miss this data. You need to ensure your scraper can execute JavaScript and wait for dynamic content to load. With tools like Playwright or Selenium, you can use explicit waits, ensuring that specific elements are loaded before the scraper proceeds.
Set a Scraping Limit
Unfortunately, sending a lot of concurrent requests can result in IP blacklisting. To prevent this from happening, you need to limit the rate at which you send requests.
Design your script so it doesn’t bombard Amazon’s servers. Setting a reasonable delay between requests, as mentioned earlier, is essential.
By implementing these advanced techniques, you’ll not only enhance the efficiency of your scraping endeavors on Amazon but also ensure longevity, reducing the chances of your scraper getting detected or blocked.
Consider Using Bright Data to Scrape Amazon
Although manual web scraping can yield results for smaller tasks, it can be tedious and less efficient when scaling up. For a more streamlined approach to harvesting vast amounts of data from Amazon, consider using Bright Data.
With the Bright Data Scraping Browser , you can interact with dynamic sites like Amazon seamlessly, as it skillfully navigates through JavaScript, AJAX requests, and other complexities. Or if you’re in a rush for structured Amazon data, be it product listings, reviews, or seller profiles, you can immediately tap into their Amazon dataset , which lets you download and access curated data directly from their platform.
Create a Bright Data Account
To get started with Bright Data, you need to create and set up your account. To do so, follow these steps:
Open your browser and go to the Bright Data website . Click on Start free trial and proceed as prompted.
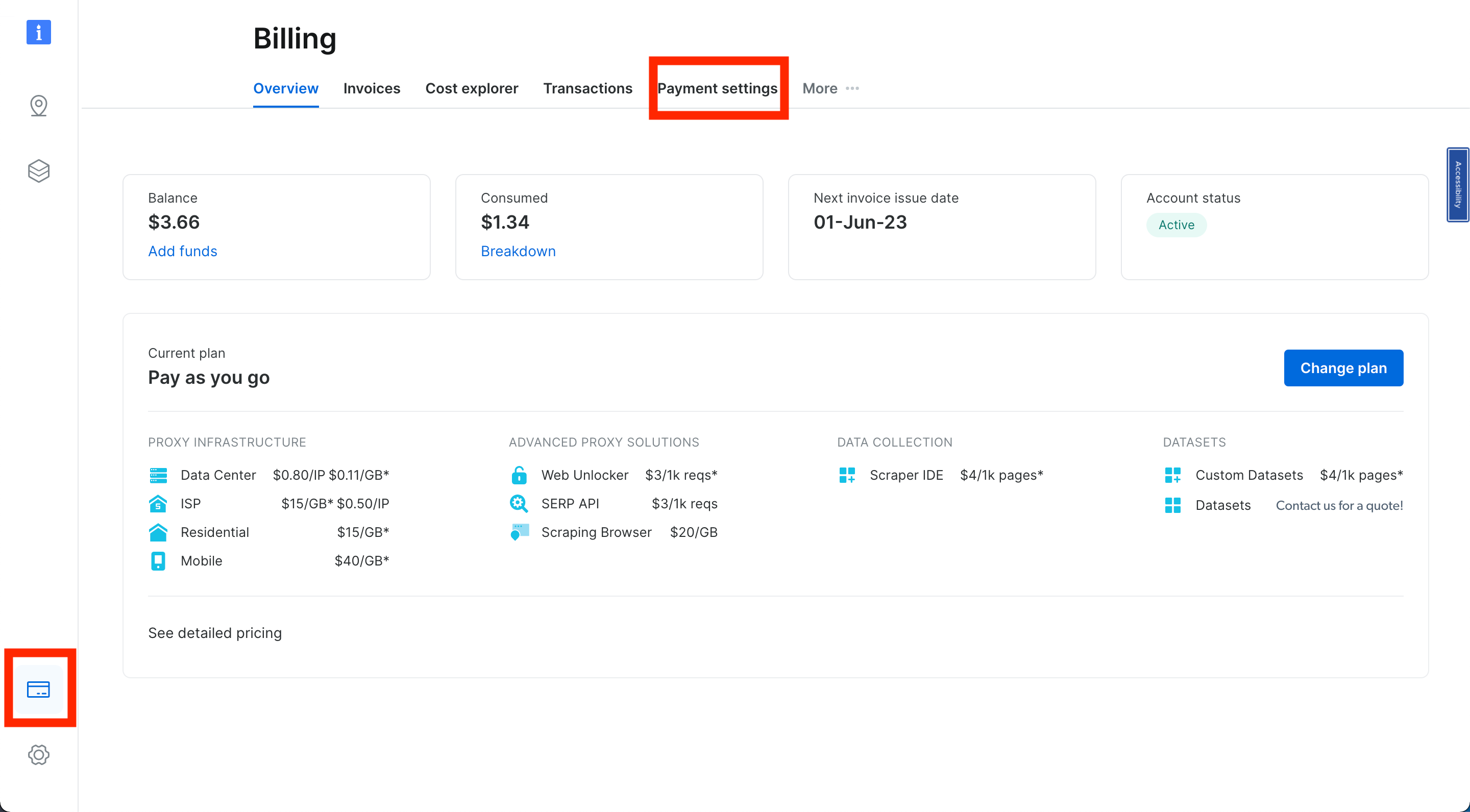
Once inside your dashboard, find the credit card icon in the left sidebar to access the Billing page. Here, introduce a valid payment method to activate your account:
Billing page.
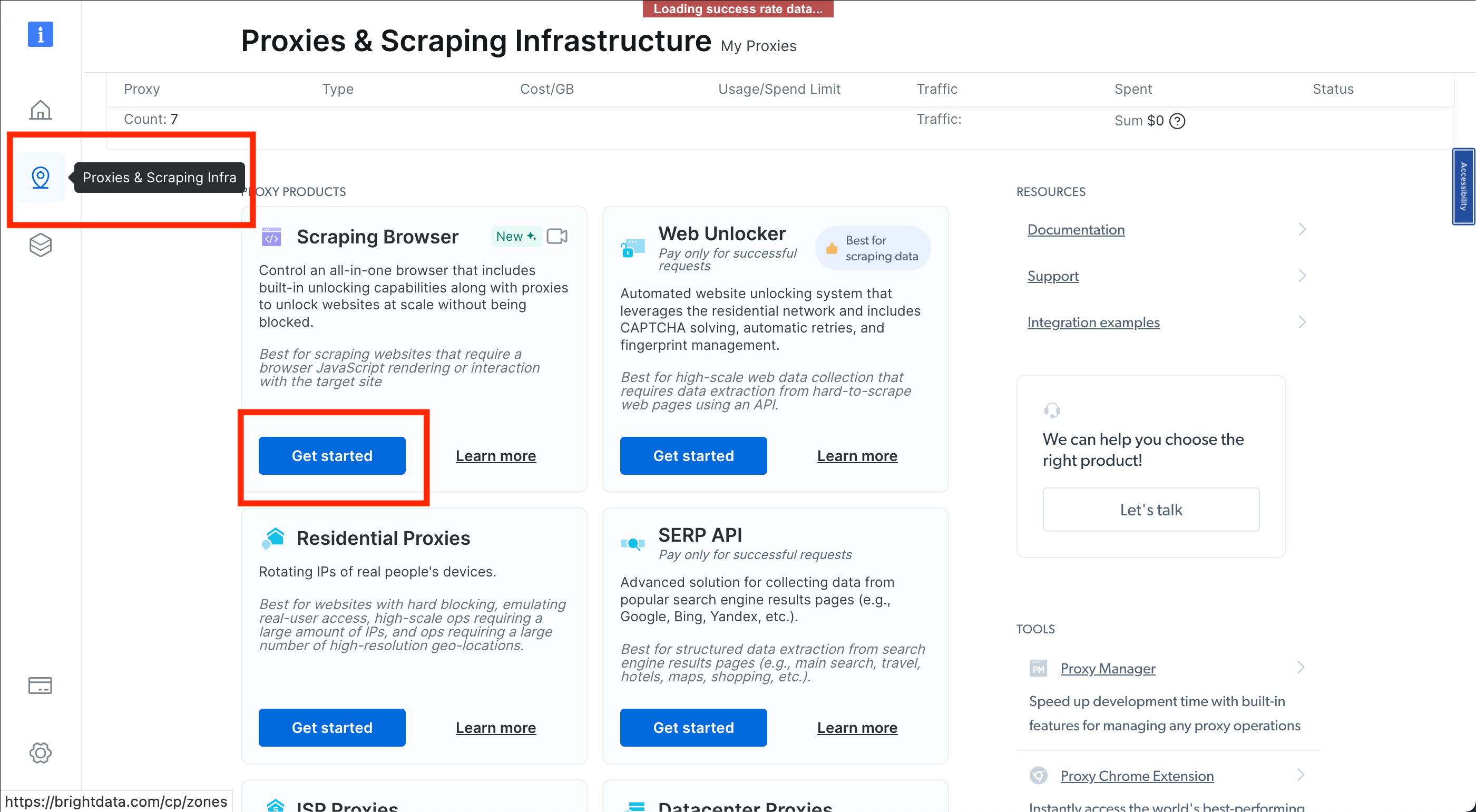
Next, head over to the Proxies & Scraping Infrastructure section by selecting its respective icon. Choose Scraping Browser > Get started :
Scraping Browser
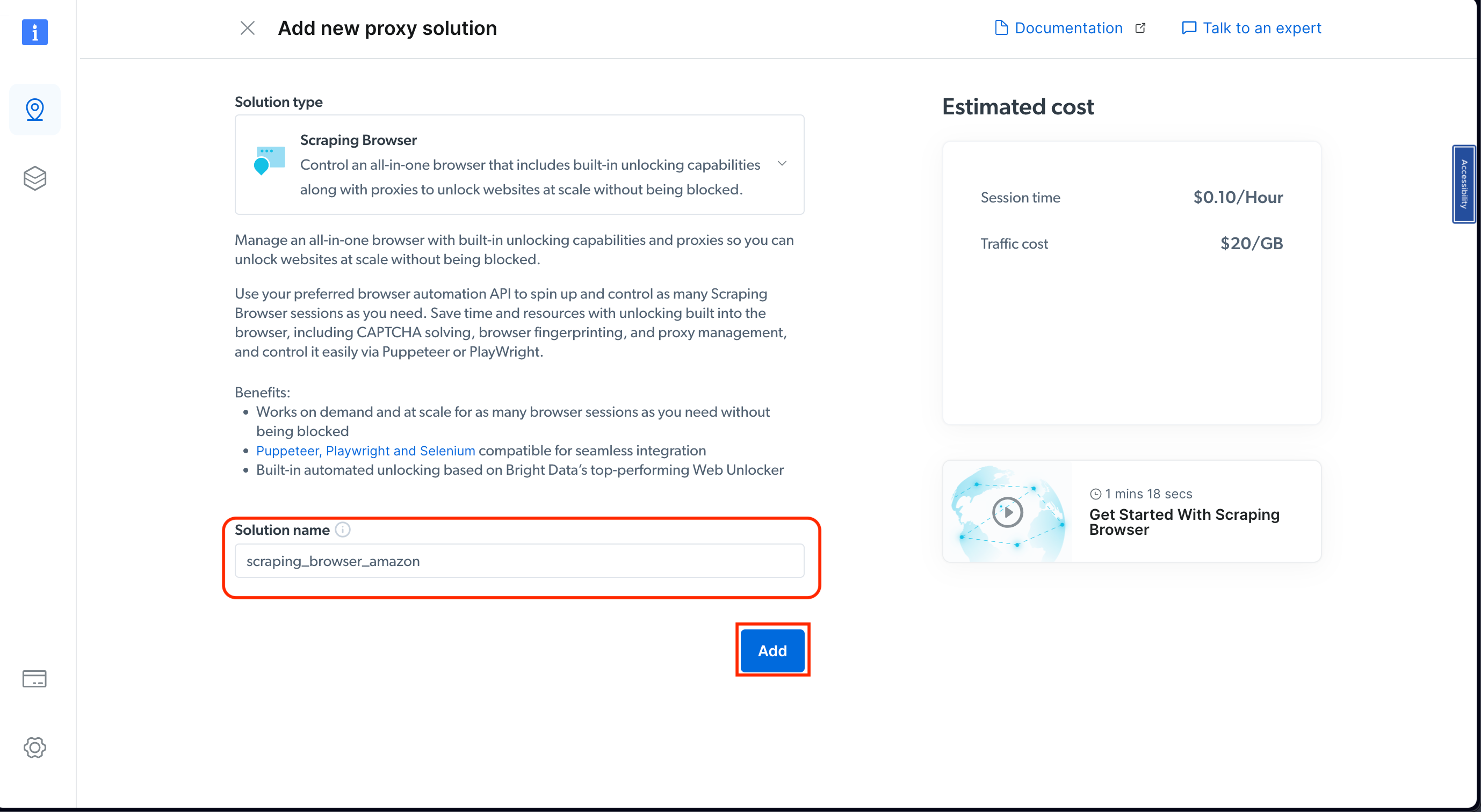
Name your solution accordingly and confirm with the Add button:
Under Access parameters , take a minute to note down your username, host(default), and password. You need these later on:
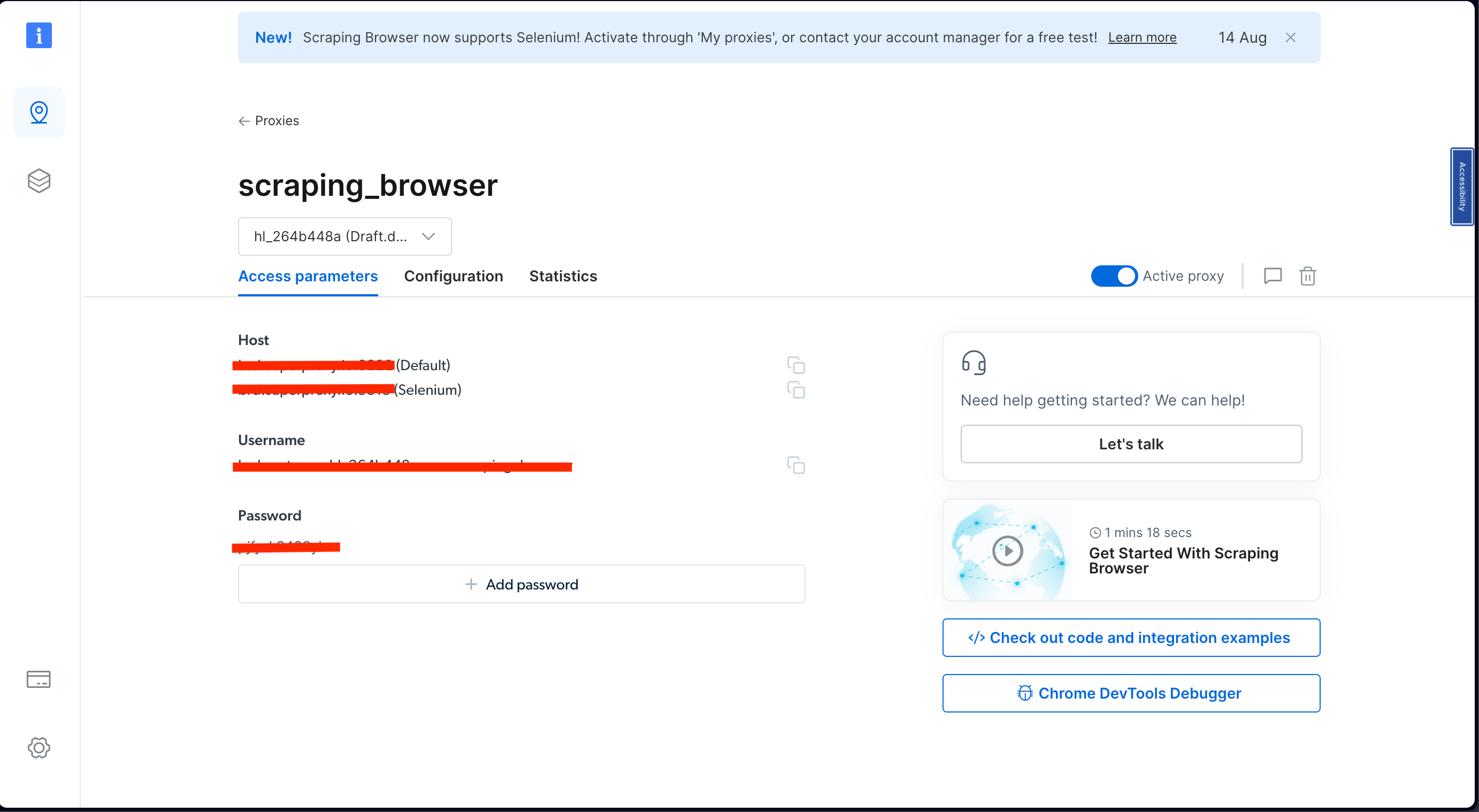
Once you’ve completed these steps, you’re ready to extract the data.
Extract Amazon Product Data Using the Scraping Browser
To start scraping product data from Amazon using Bright Data, create a new file named
amazon_scraper_bdata.py
and add the following code to it:
import asyncio
from playwright.async_api import async_playwright
import pandas as pd
username='YOUR_BRIGHTDATA_USERNAME'
password='YOUR_BRIGHTDATA_PASSWORD'
auth=f'{username}:{password}'
host = 'YOUR_BRIGHTDATA_DEFAULT_HOST'
browser_url = f'wss://{auth}@{host}'
async def scrape_amazon_bdata():
async with async_playwright() as pw:
print('connecting')
# Launch new browser
browser = await pw.chromium.connect_over_cdp(browser_url)
print('connected')
page = await browser.new_page()
print('navigating')
# Go to Amazon URL
await page.goto('https://www.amazon.com/s?i=fashion&bbn=115958409011', timeout=600000)
print('data extraction in progress')
# Extract information
results = []
listings = await page.query_selector_all('div.a-section.a-spacing-small')
for listing in listings:
result = {}
# Product name
name_element = await listing.query_selector('h2.a-size-mini > a > span')
result['product_name'] = await name_element.inner_text() if name_element else 'N/A'
# Rating
rating_element = await listing.query_selector('span[aria-label*="out of 5 stars"] > span.a-size-base')
result['rating'] = (await rating_element.inner_text())[0:3]await rating_element.inner_text() if rating_element else 'N/A'
# Number of reviews
reviews_element = await listing.query_selector('span[aria-label*="stars"] + span > a > span')
result['number_of_reviews'] = await reviews_element.inner_text() if reviews_element else 'N/A'
# Price
price_element = await listing.query_selector('span.a-price > span.a-offscreen')
result['price'] = await price_element.inner_text() if price_element else 'N/A'
if(result['product_name']=='N/A' and result['rating']=='N/A' and result['number_of_reviews']=='N/A' and result['price']=='N/A'):
pass
else:
results.append(result)
# Close browser
await browser.close()
return results
# Run the scraper and save results to a CSV file
results = asyncio.run(scrape_amazon_bdata())
df = pd.DataFrame(results)
df.to_csv('amazon_products_bdata_listings.csv', index=False)
In this code, you’re utilizing the
Playwright
library in combination with
asyncio
to asynchronously scrape product details from an Amazon web page. You’ve set up authentication details for Bright Data, a proxy service, and then connect to a browser using this service.
Once connected, the script navigates to the specified Amazon URL, extracts product information, such as name, rating, number of reviews, and price, and then compiles these details into a list. If a particular product doesn’t have any of the aforementioned data, it’s skipped.
After the scraping is done, the browser is closed, and the extracted product details are saved into a CSV file named
amazon_products_bdata_listings.csv
.
Important:
Remember to substitute
YOUR_BRIGHTDATA_USERNAME
,
YOUR_BRIGHTDATA_PASSWORD
, and
YOUR_BRIGHTDATA_HOST
with your unique Bright Data zoneaccount details (found in the “Access parameters” tab).
Important:
Remember to substitute
YOUR_BRIGHTDATA_USERNAME
,
YOUR_BRIGHTDATA_PASSWORD
, and
YOUR_BRIGHTDATA_HOST
with your unique Bright Data zoneaccount details (found in the “Access parameters” tab).
Run the code from your terminal or shell using the following command:
python3 amazon_scraper_bdata.py
Your output should look like this:
product_name,rating,number_of_reviews,price
Women's Square Neck Bodice Dress Sleeveless Tank Top Stretch Flare Mini Dresses,N/A,131,$32.99
"Women's Swiftwater Sandal, Lightweight and Sporty Sandals for Women",N/A,"35,941",$19.95
Women's Elegant Sleeveless Off Shoulder Bodycon Long Formal Party Evening Dress,N/A,"3,122",$49.99
Women 2023 Summer Sleeveless Tank Dresses Crew Neck Slim Fit Short Casual Ruched Bodycon Party Club Mini Dress,N/A,"40,245",$33.99
"Infinity Dress with Bandeau, Convertible Bridesmaid Dress, Long, Plus Size, Multi-Way Dress, Twist Wrap Dress",N/A,"11,412",$49.99
…output omitted…
Although manually scraping Amazon can encounter issues, such as CAPTCHAs and access restrictions, the Bright Data Scraping Browser provides the resilience and flexibility to address these challenges, securing uninterrupted data extraction.
Amazon Scraper API
Scrape Amazon data like ASIN, seller name, title, brand, description, and images on demand without worrying about infrastructure, proxies, or getting blocked. Maintain full control and flexibility for your data collection needs, and retrieve structured results in multiple formats via a simple, no-code interface. Start your free Amazon Scraper API trial today.
Scrape Amazon on demand
Retrieve results in multiple formats
No-code interface for rapid development
Bright Data Amazon Dataset
If you don’t want to scrape data manually, Bright Data also offers ready-made Amazon datasets . In these datasets, you’ll find everything from product details to user reviews. Using these datasets means you don’t have to scrape websites yourself, and the data is already organized for you.
To find these datasets, go to your Bright Data Dashboard and click on Web Data on the left. Then click on Get Data from the Dataset Marketplace :
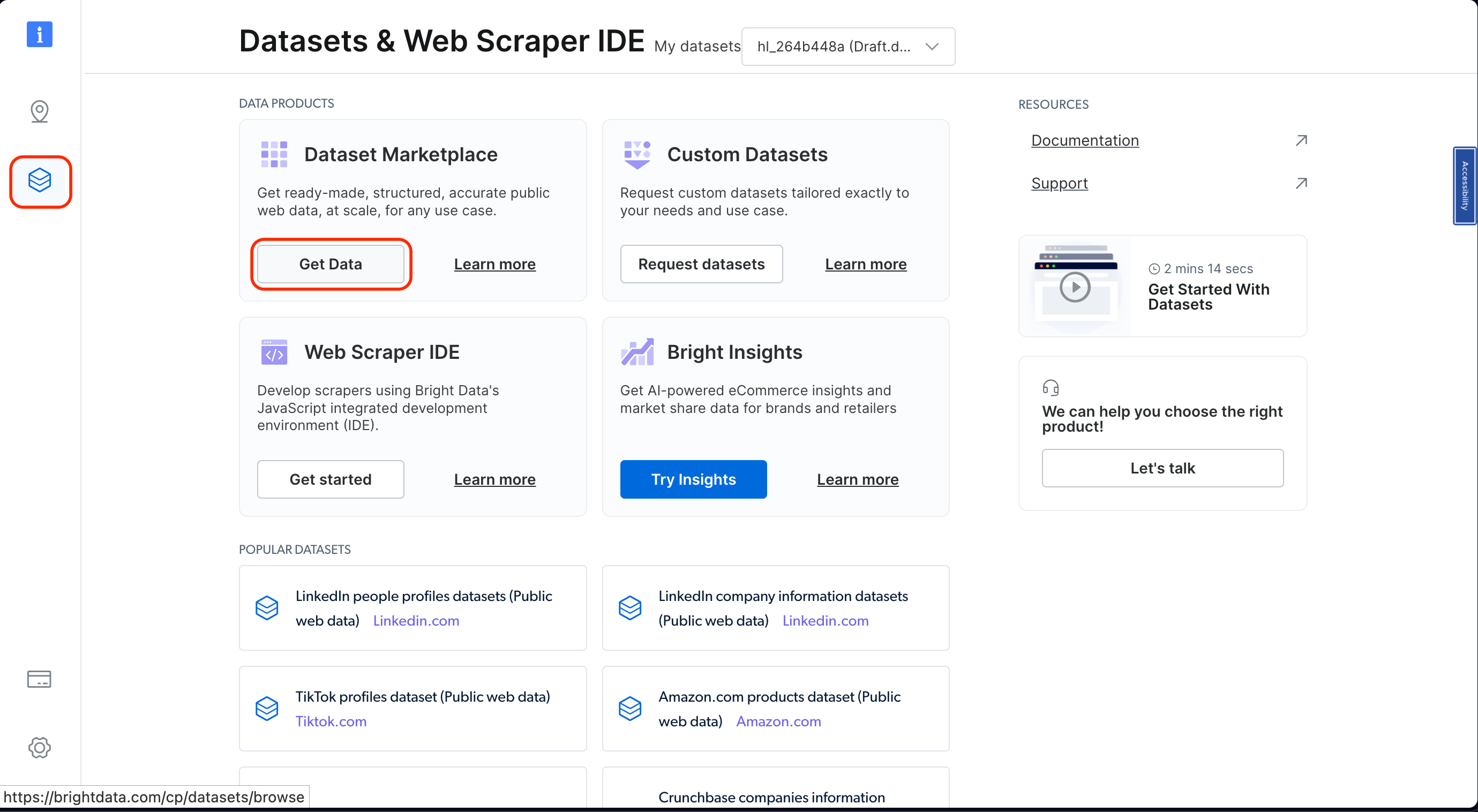
Next, search for “amazon” in the search bar. Then click on View dataset :
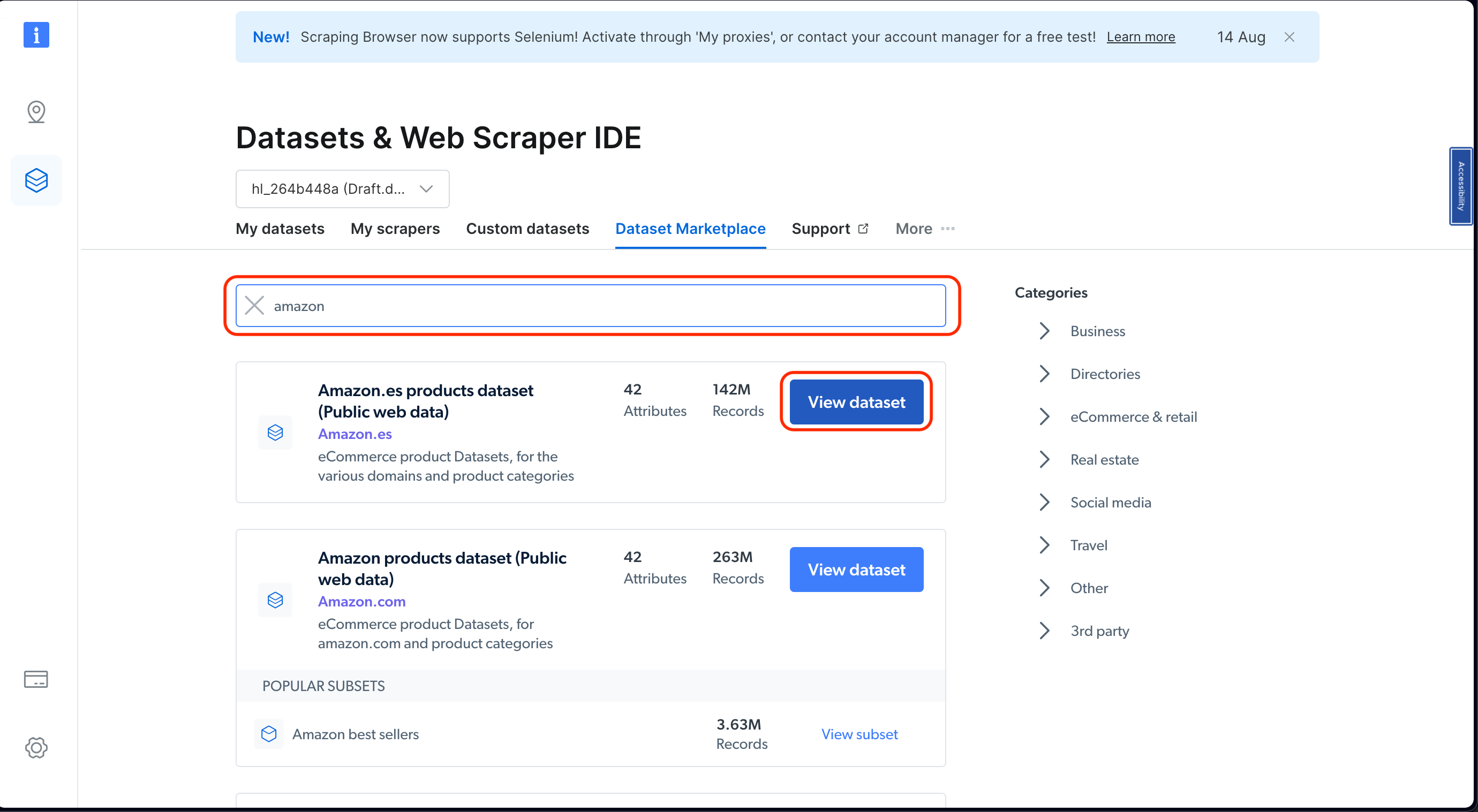
Pick the dataset that fits what you need. You can use filters to narrow down your choices. Remember, the cost depends on how much data you want, so you can choose based on what you need and your budget:
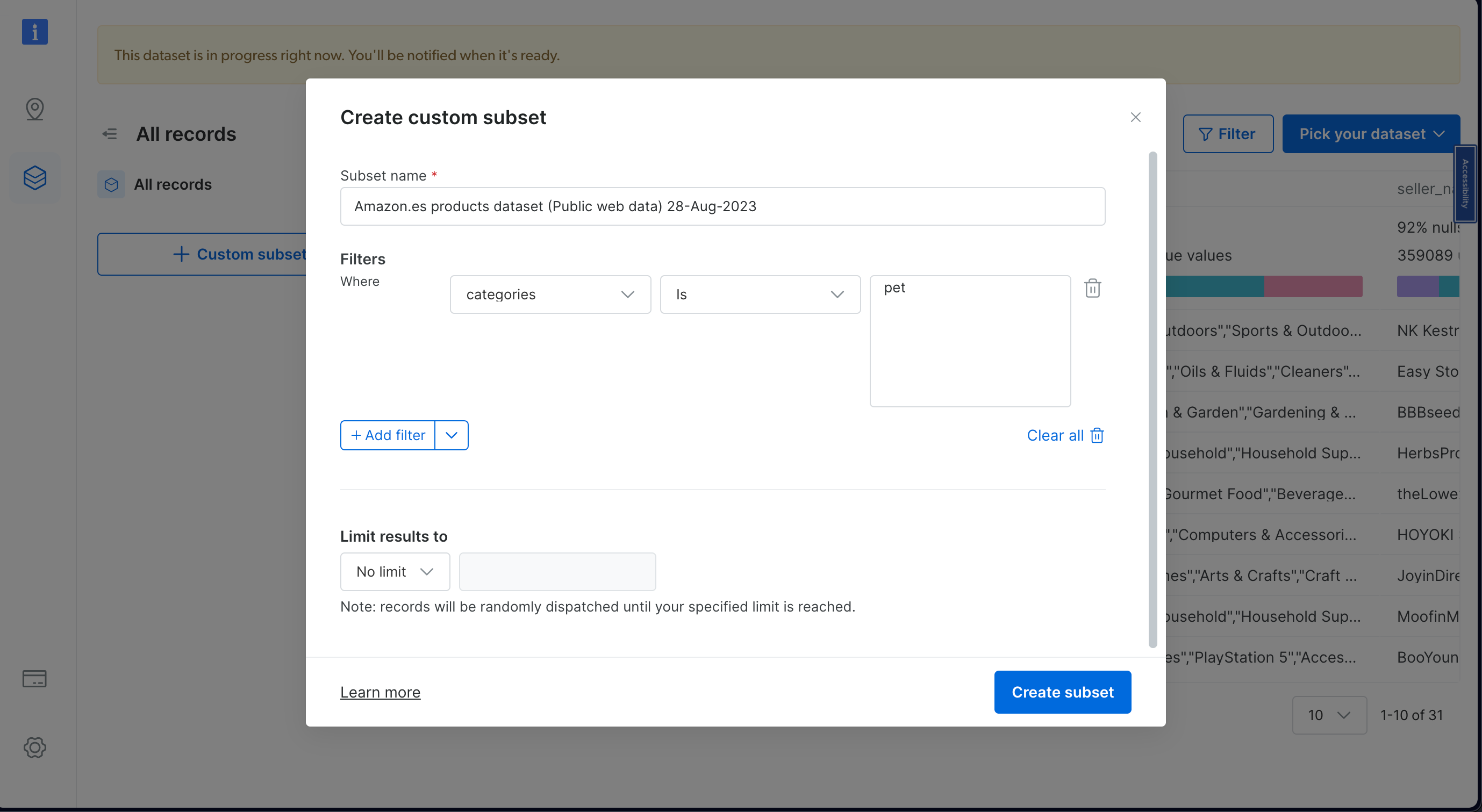
You can find the code that is used in this tutorial on the following GitHub repository .
Conclusion
In this tutorial, you learned how to gather data from Amazon manually using Python, which comes with its fair challenges like CAPTCHAs and rate-limiting that could hinder efficient data scraping. However, leveraging tools from Bright Data and its Scraping Browser can streamline the process and mitigate these issues.
Bright Data provides tools that simplify data collection from websites, including Amazon. The Amazon Scraper API is a great solution for those looking for a no-code interface and quick data extraction.
Additionally, Bright Data offers ready-to-use datasets, specifically for Amazon. This means you don’t have to start from scratch; you can directly access vast amounts of Amazon data.
By using Bright Data tools, collecting data becomes a breeze, opening doors to fresh insights and knowledge. Dive in and discover new data possibilities with Bright Data!
Note: This guide was thoroughly tested by our team at the time of writing, but as websites frequently update their code and structure, some steps may no longer work as expected.