How to Build an Agentic RAG System with Bright Data
{ "@context": "https://schema.org", "@type": "HowTo", "name": "How to Build an Agentic RAG with Bright Data", "description": "Step-by-step guide to building an Agentic Retrieval-Augmented Generation (RAG) system that pulls live web data using Bright Data, embeds it in a vector database with Pinecone, and generates answers with OpenAI.", "step": [ { "@type": "HowToStep", "name": "Set up your project environment", "text": "Create a new project directory, open it in your code editor, and set up a Python virtual environment." }, { "@type": "HowToStep", "name": "Implement the Bright Data retriever", "text": "Install the requests library, import required modules, and write a script to trigger scraping using your Bright Data API key and dataset information." }, { "@type": "HowToStep", "name": "Scrape and save web data", "text": "Submit the list of URLs to Bright Data's Web Scraper API, poll for completion, and save the result as a JSON file." }, { "@type": "HowToStep", "name": "Process and embed the scraped data", "text": "Install openai, pinecone, and pandas. Load the scraped data, preprocess/clean the text, generate text embeddings using OpenAI, and upsert them into your Pinecone vector database." }, { "@type": "HowToStep", "name": "Build vector search and answer generation", "text": "Write functions to search Pinecone for relevant documents and to generate answers using OpenAI’s models, optionally including context from retrieved documents." }, { "@type": "HowToStep", "name": "Implement the Agent Controller", "text": "Develop a controller that decides whether to use vector database results or fallback to a generic LLM response, based on search relevance." }, { "@type": "HowToStep", "name": "Orchestrate the Agentic RAG workflow", "text": "Initialize all components in your main script, provide API keys, and trigger the agentic response logic for your queries." }, { "@type": "HowToStep", "name": "Add a user feedback loop (optional)", "text": "After serving an answer, collect user feedback. If negative, relax search constraints and retry the retrieval/generation process." } ], "estimatedCost": { "@type": "MonetaryAmount", "currency": "USD", "value": "Free" }, "supply": [ { "@type": "HowToSupply", "name": "Bright Data account and API key" }, { "@type": "HowToSupply", "name": "OpenAI API key" }, { "@type": "HowToSupply", "name": "Pinecone API key" } ], "tool": [ { "@type": "HowToTool", "name": "Python 3" }, { "@type": "HowToTool", "name": "requests library" }, { "@type": "HowToTool", "name": "Bright Data Web Scraper API" }, { "@type": "HowToTool", "name": "OpenAI Python SDK" }, { "@type": "HowToTool", "name": "Pinecone Python SDK" }, { "@type": "HowToTool", "name": "pandas" } ], "totalTime": "PT30M" }
In this guide, you will learn:
What Agentic Retrieval-Augmented Generation (RAG) is and why adding agentic capabilities matters
How Bright Data enables autonomous and live web data retrieval for RAG systems
How to process and clean web-scraped data for embedding generation
Implementing an agent controller to orchestrate between vector search and LLM text generation
Designing a feedback loop to capture user inputs and optimize retrieval and generation dynamically
Let’s dive in!
The rise of Artificial Intelligence (AI) has introduced new concepts, including Agentic RAG. In simple terms, Agentic RAG is Retrieval Augmented Generation (RAG) that integrates AI agents. As the name suggests, RAG is an information retrieval system that follows a linear process: it receives a query, retrieves relevant information, and generates a response.
Why combine AI agents with RAG?
A recent survey shows that nearly two-thirds of workflows using AI agents report increased productivity. In addition, close to 60 percent report cost savings. This makes combining AI agents with RAG a potential game-changer for modern retrieval workflows.
Agentic RAG offers advanced capabilities. Unlike traditional RAG systems, it can not only retrieve data but also decide to fetch information from external sources, such as live web data embedded in a database .
This article demonstrates how to build an Agentic RAG system that retrieves news information using Bright Data for web data collection, Pinecone as a vector database, OpenAI for text generation, and Agno as the agent controller.
Overview of Bright Data
Whether you are sourcing from a live data stream or using prepared data from your database, the quality of output from your Agentic RAG system depends on the quality of the data it receives. That is where Bright Data becomes essential.
Bright Data provides reliable, structured, and up-to-date web data for a wide range of use cases. With Bright Data’s Web Scraper API , which has access to more than 120 domains, web scraping is more efficient than ever. It handles common scraping challenges such as IP bans, CAPTCHA, cookies, and other forms of bot detection.
To get started, sign up for a free trial, then obtain your API key and
dataset_id
for the domain you want to scrape. Once you have these, you are ready to begin.
Below are the steps to retrieve fresh data from a popular domain like BBC News:
Create a Bright Data account if you have not already done so. A free trial is available.
Go to the Web Scrapers page. Under Web Scrapers Library , explore the available scraper templates.
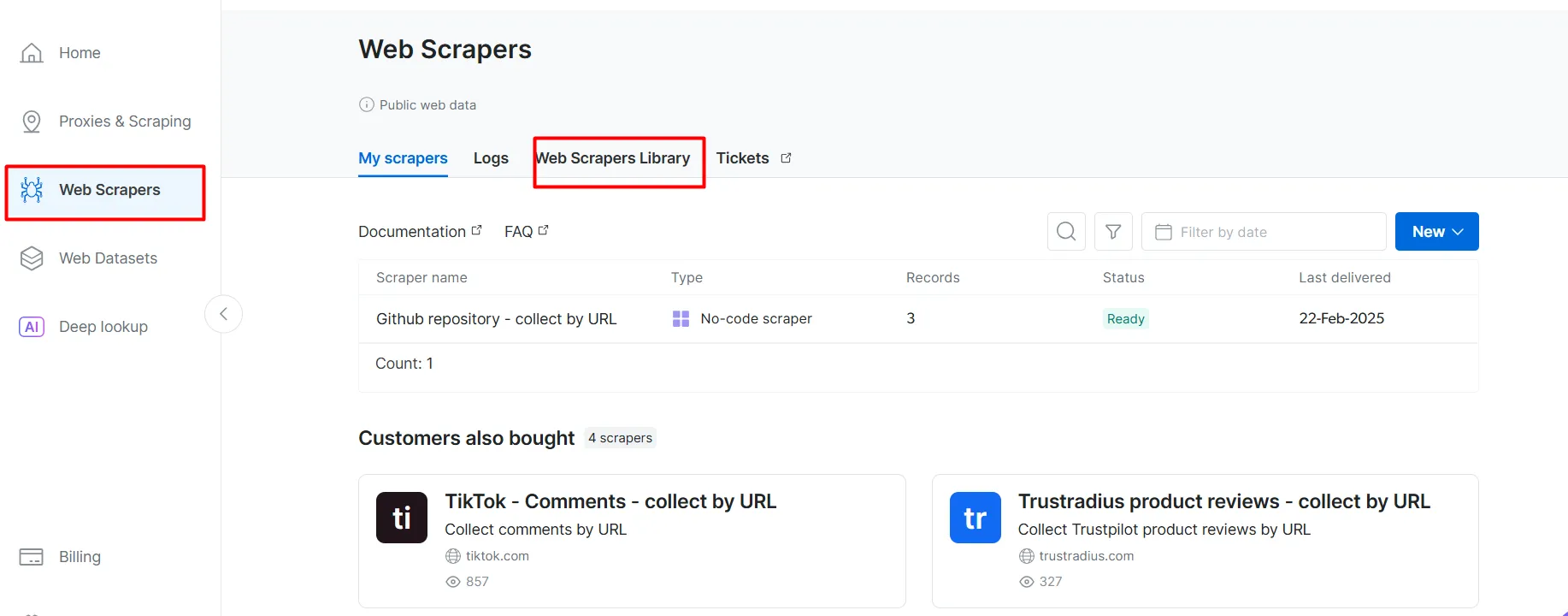
Search for your target domain, such as BBC News , and select it.
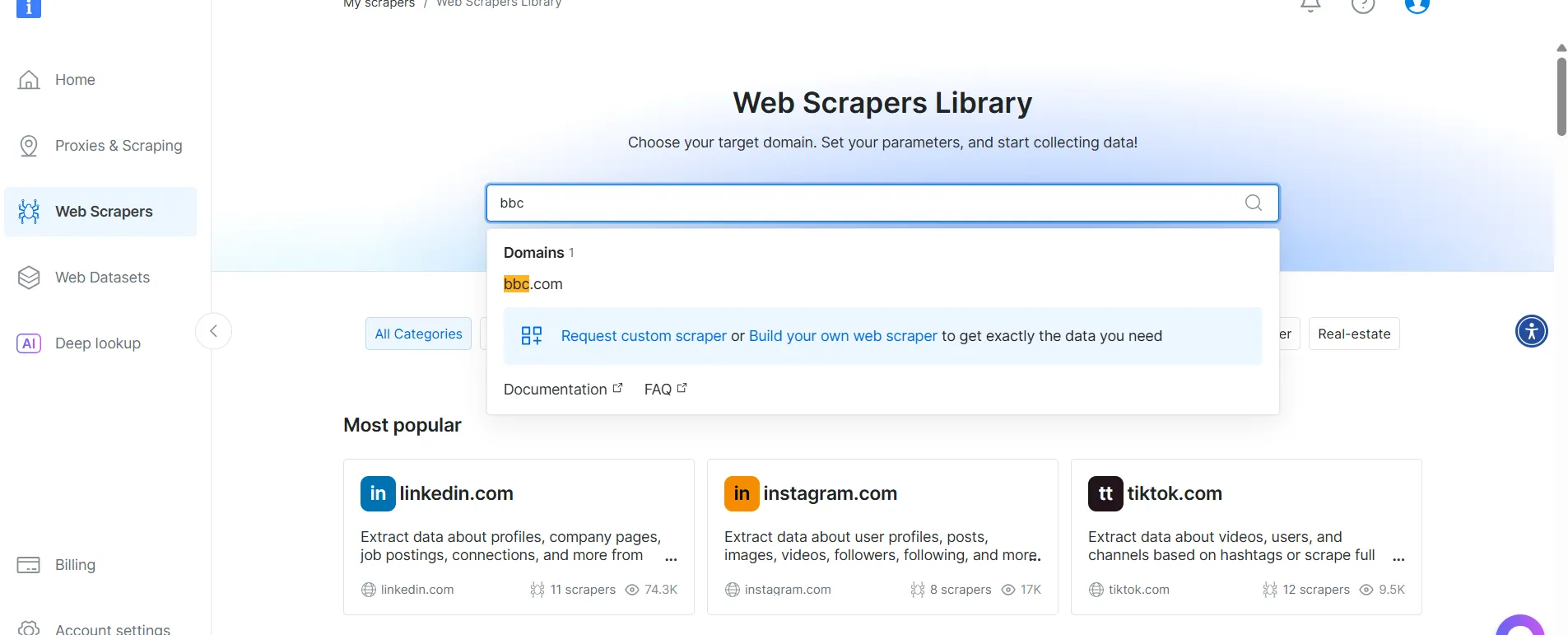
From the list of BBC News scrapers, select BBC News — collect by URL . This scraper allows you to retrieve data without logging in to the domain.
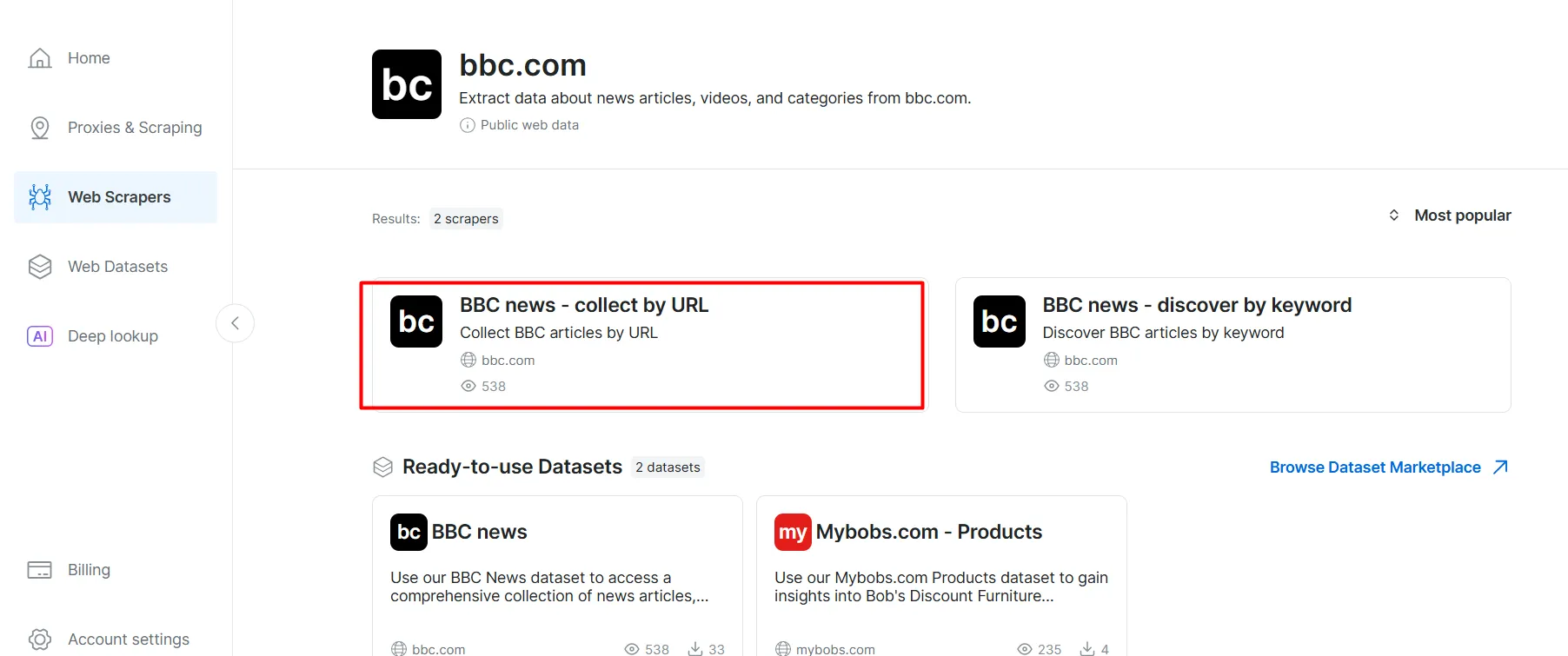
Choose the Scraper API option. The No-Code Scraper helps to retrieve datasets without code.
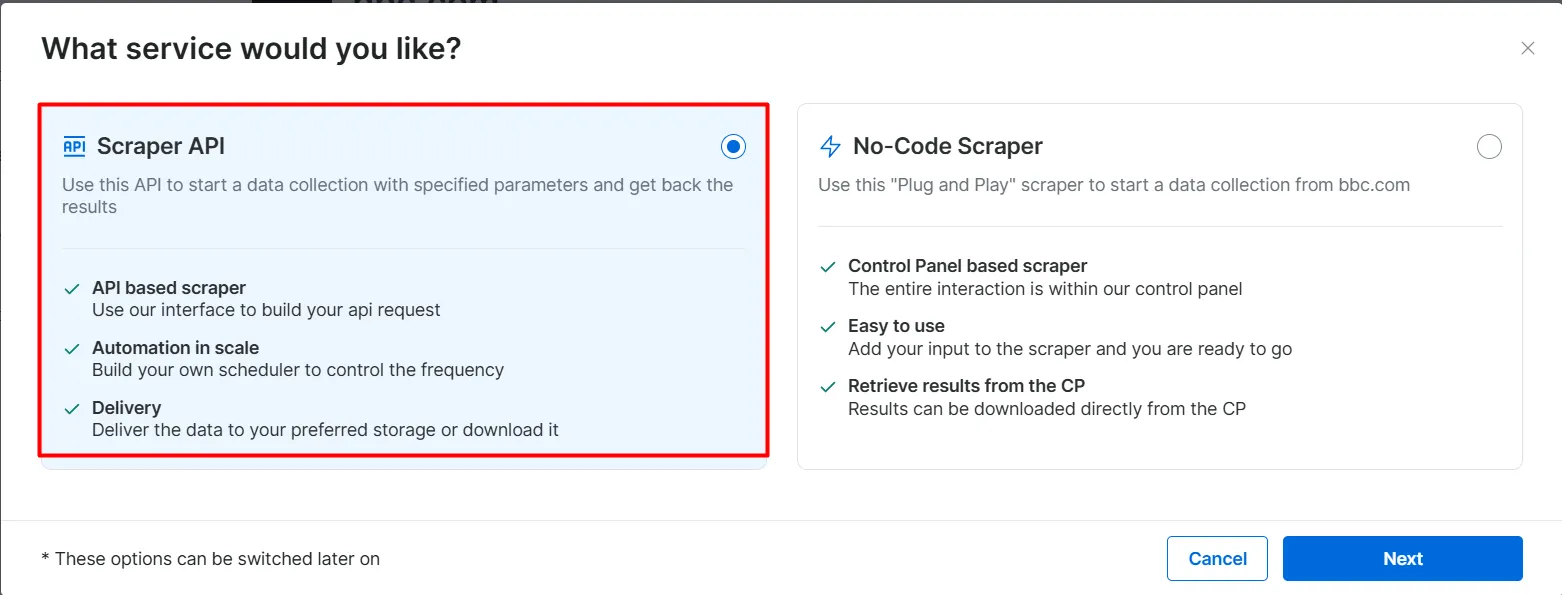
Click
API Request Builder
, then copy your
API-key
,
BBC Dataset URL
, and
dataset_id
. You will use these in the next section when building the Agentic RAG workflow.
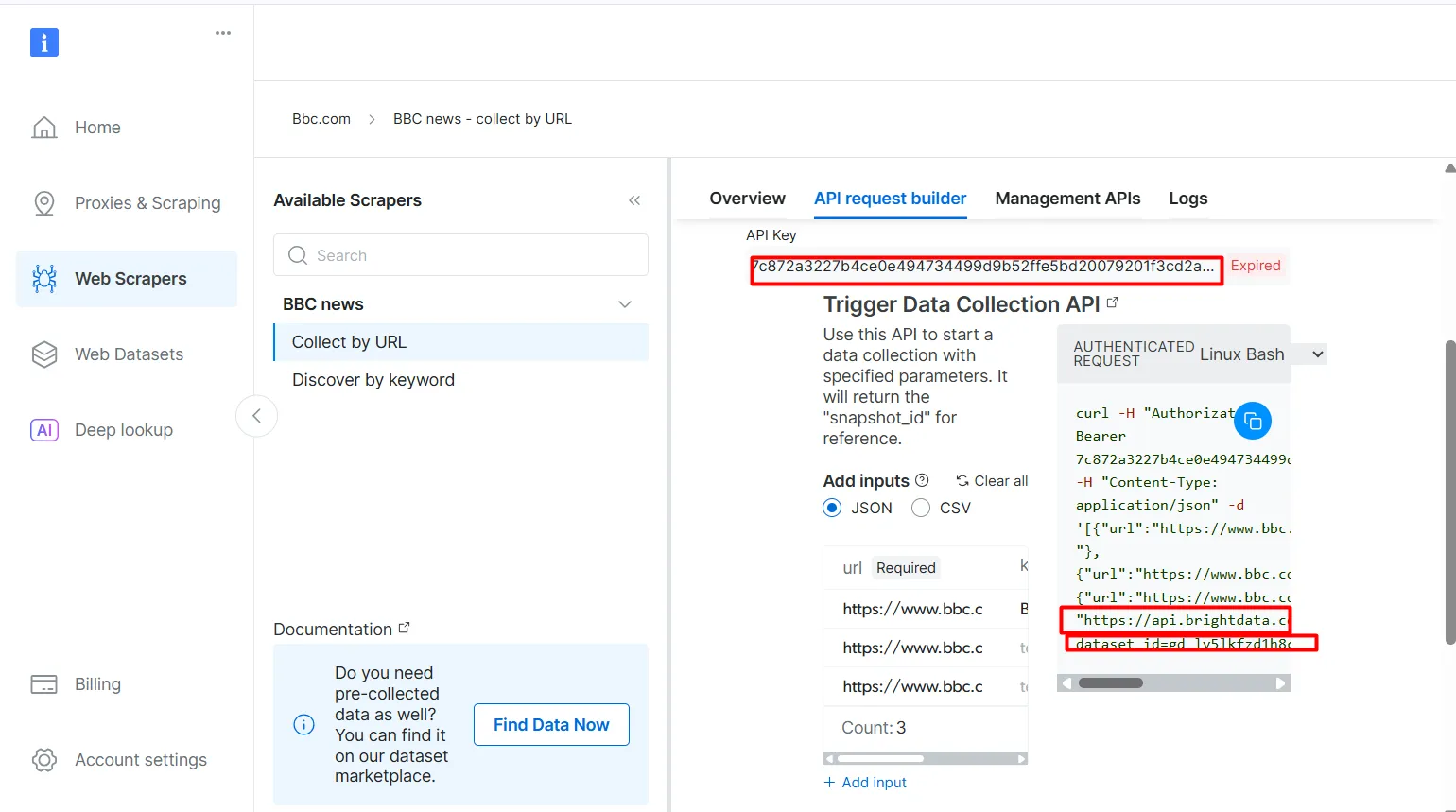
The
API-key
and
dataset_id
are required to enable agentic capabilities in your workflow. They allow you to embed live data into your vector database and support real-time queries, even when the search query does not directly match the pre-indexed content.
Prerequisites
Before you begin, make sure you have the following:
A Bright Data account
An OpenAI API key Sign up on OpenAI to obtain your API key:
A Pinecone API key Refer to the Pinecone documentation and follow the instructions in the Get an API key section.
A basic understanding of Python You can install Python from the official website
A basic understanding of RAG and agent concepts
Structure of the Agentic RAG
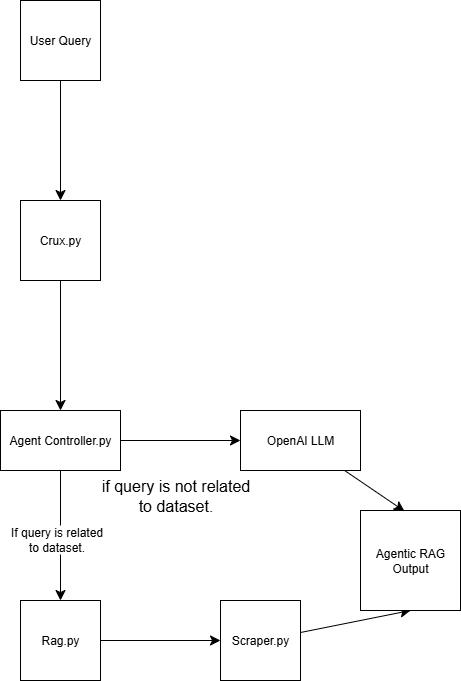
This Agentic RAG system is built using four scripts:
scraper.py
Retrieves web data via Bright Data
rag.py
Embeds data into the
vector database
(Pinecone) Note: A vector (numerical embedding) database is used because it stores unstructured data typically generated by a machine learning model. This format is ideal for similarity search in retrieval tasks.
agent_controller.py
Contains the control logic. It determines whether to use preprocessed data from the vector database or rely on general knowledge from GPT, depending on the nature of the query
crux.py
Acts as the core of the Agentic RAG system. It stores the API keys and initializes the workflow.
Your agentic rag structure will look like this at the end of the demo:
the agentic RAG final structure
Building Agentic RAG with Bright Data
Step 1: Set Up the Project
1.1 Create a new project directory
Create a folder for your project and navigate into it:
mkdir agentic-rag
cd agentic-rag
1.2 Open the project in Visual Studio Code
Launch Visual Studio Code and open the newly created directory:
.../Desktop/agentic-rag> code .
1.3 Set up and activate a virtual environment
To set up a virtual environment, run:
python -m venv venv
Alternatively, in Visual Studio Code, follow the prompts in the Python environments guide to create a virtual environment.
To activate the environment:
On Windows:
.venv\\Scripts\\activate
On macOS or Linux:
source venv/bin/activate
Step 2: Implement the Bright Data Retriever
2.1 Install the requests library in your scraper.py file
pip install requests
2.2 Import the following modules
import requests
import json
import time
2.3 Set up your credentials
Use the Bright Data
API key
,
dataset URL
, and
dataset_id
you copied earlier.
def trigger_bbc_news_articles_scraping(api_key, urls):
# Endpoint to trigger the Web Scraper API task
url = "<https://api.brightdata.com/datasets/v3/trigger>"
params = {
"dataset_id": "gd_ly5lkfzd1h8c85feyh", # ID of the BBC web scraper
"include_errors": "true",
}
# Convert the input data in the desired format to call the API
data = [{"url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
2.4 Set up the response logic
Populate your request with the URLs of the pages you want to scrape. In this case, focus on sports-related articles.
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Request successful! Response: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"<https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json>"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
# Write the snapshot to an output json file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
return
elif response.status_code == 202:
print(F"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "BRIGHT DATA KEY" # Replace it with your Bright Data's Web Scraper API key
# URLs of BBC articles to retrieve data from
urls = [
"<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"<https://www.bbc.com/sport/formula1/articles/cgenqvv9309o>",
"<https://www.bbc.com/sport/formula1/articles/c78jng0q2dxo>",
"<https://www.bbc.com/sport/formula1/articles/cdrgdm4ye53o>",
"<https://www.bbc.com/sport/formula1/articles/czed4jk7eeeo>",
"<https://www.bbc.com/sport/football/articles/c807p94r41do>",
"<https://www.bbc.com/sport/football/articles/crgglxwge10o>",
"<https://www.bbc.com/sport/tennis/articles/cy700xne614o>",
"<https://www.bbc.com/sport/tennis/articles/c787dk9923ro>",
"<https://www.bbc.com/sport/golf/articles/ce3vjjq4dqzo>"
]
snapshot_id = trigger_bbc_news_articles_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "news-data.json")
2.5 Run the code
After running the script, a file named
news-data.json
will appear in your project folder. It contains the scraped article data in structured JSON format.
Here is an example of the content inside the JSON file:
[
{
"id": "c9dj0elnexyo",
"url": "<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"author": "BBC",
"headline": "Max Verstappen: Red Bull adviser Helmut Marko has 'great concern' about world champion's future with team",
"topics": [
"Formula 1"
],
"publication_date": "2025-04-14T13:42:08.154Z",
"content": "Saudi Arabian Grand PrixVenue: Jeddah Dates: 18-20 April Race start: 18:00 BST on SundayCoverage: Live radio commentary of practice, qualifying and race online and BBC 5 Sports Extra; live text updates on the BBC Sport website and app; Red Bull motorsport adviser Helmut Marko says he has \\"great concern\\" about Max Verstappen's future with the team in the context of their current struggles.AdvertisementThe four-time champion finished sixth in the Bahrain Grand Prix on Sunday, while Oscar Piastri scored McLaren's third win in four races so far this year.Dutchman Verstappen is third in the drivers' championship, eight points behind leader Lando Norris of McLaren.Marko told Sky Germany: \\"The concern is great. Improvements have to come in the near future so that he has a car with which he can win again.\\"We have to create a basis with a car so that he can fight for the world championship.\\"Verstappen has a contract with Red Bull until 2028. But Marko told BBC Sport this month that it contains a performance clause that could allow him to leave the team.; The wording of this clause is not known publicly but it effectively says that Red Bull have to provide Verstappen with a winning car.Verstappen won the Japanese Grand Prix a week before Bahrain but that victory was founded on a pole position lap that many F1 observers regarded as one of the greatest of all time.Because overtaking was next to impossible at Suzuka, Verstappen was able to hold back the McLarens of Norris and Piastri and take his first win of the year.Verstappen has qualified third, fourth and seventh for the other three races in Australia, China and Bahrain.The Red Bull is on average over all qualifying sessions this year the second fastest car but 0.214 seconds a lap slower than the McLaren.Verstappen has complained all year about balance problems with the Red Bull, which is unpredictable on corner entry and has mid-corner understeer.Red Bull team principal Christian Horner admitted after the race in Bahrain that the car's balance problems were fundamentally similar to the ones that made the second half of last year a struggle for Verstappen.He won just twice in the final 13 races of last season, but managed to win his fourth world title because of the huge lead he built up when Red Bull were in dominant form in the first five races of the season.Horner also said the team were having difficulties with correlation between their wind tunnel and on-track performance. Essentially, the car performs differently on track than the team's simulation tools say it should.; Verstappen had a difficult race in Bahrain including delays at both pit stops, one with the pit-lane traffic light system and one with fitting a front wheel.At one stage he was running last, and he managed to snatch sixth place from Alpine's Pierre Gasly only on the last lap.Verstappen said that the hot weather and rough track surface had accentuated Red Bull's problems.He said: \\"Here you just get punished a bit harder when you have big balance issues because the Tarmac is so aggressive.\\"The wind is also quite high and the track has quite low grip, so everything is highlighted more.\\"Just the whole weekend struggling a bit with brake feeling and stopping power, and besides that also very poor grip. We tried a lot on the set-up and basically all of it didn't work, didn't give us a clear direction to work in.\\"Verstappen has said this year that he is \\"relaxed\\" about his future.Any decision about moving teams for 2026 is complicated by the fact that F1 is introducing new chassis and engine rules that amount to the biggest regulation change in the sport's history, and it is impossible to know which team will be in the best shape.But it is widely accepted in the paddock that Mercedes are looking the best in terms of engine performance for 2026.Mercedes F1 boss Toto Wolff has made no secret of his desire to sign Verstappen.The two parties had talks last season but have yet to have any discussions this season about the future.",
"videos": [],
"images": [
{
"image_url": "<https://ichef.bbci.co.uk/ace/branded_sport/1200/cpsprodpb/bfc4/live/d3cc7850-1931-11f0-869a-33b652e8958c.jpg>",
"image_description": "Main image"
},
Now that you have the data, the next step is to embed it.
Step 3: Set Up Embeddings and Vector Store
3.1 Install the required libraries in your rag.py file
pip install openai pinecone pandas
3.2 Import the required libraries
import json
import time
import re
import openai
import pandas as pd
from pinecone import Pinecone, ServerlessSpec
3.3 Configure your OpenAI key
Use OpenAI to generate embeddings from the
text_for_embedding
field.
# Configure your OpenAI API key here or pass to functions
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI API key
3.4 Configure your Pinecone API key and index settings
Set up the Pinecone environment and define your index configuration.
pinecone_api_key = "PINECONE_API_KEY" # Replace with your Pinecone API key
index_name = "news-articles"
dimension = 1536 # OpenAI embedding dimension for text-embedding-ada-002 (adjust if needed)
namespace = "default"
3.5 Initialize the Pinecone client and index
Ensure the client and index are properly initialized for data storage and retrieval.
# Initialize Pinecone client and index
pc = Pinecone(api_key=pinecone_api_key)
# Check if index exists
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=dimension,
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
while not pc.describe_index(index_name).status["ready"]:
time.sleep(1)
pinecone_index = pc.Index(index_name)
print(pinecone_index)
3.6 Clean, load, and preprocess data
# Text cleaning helper
def clean_text(text):
text = re.sub(r"\\s+", " ", text)
return text.strip()
# Load and preprocess `news-data.json`
def load_and_prepare_data(json_path="news-data.json"):
with open(json_path, "r", encoding="utf-8") as f:
news_data = json.load(f)
df = pd.DataFrame(news_data)
df["text_for_embedding"] = df["headline"].map(clean_text) + ". " + df["content"].map(clean_text)
df["id"] = df["id"].astype(str)
return df
Note: You can rerun
scraper.py
to make sure your data is current.
Note: You can rerun
scraper.py
to make sure your data is current.
3.7 Generate embeddings using OpenAI
Create embeddings from your preprocessed text using OpenAI’s embedding model.
# New embedding generation via OpenAI API
def openai_generate_embeddings(texts, model="text-embedding-ada-002"):
openai.api_key = OPENAI_API_KEY
# OpenAI endpoint accepts a list of strings and returns list of embeddings
response = openai.embeddings.create(
input=texts,
model=model
)
embeddings = [datum.embedding for datum in response.data]
return embeddings
3.8 Update Pinecone with embeddings
Push the generated embeddings to Pinecone to keep the vector database up to date.
# Embed and upsert to Pinecone
def embed_and_upsert(json_path="news-data.json", namespace=namespace):
df = load_and_prepare_data(json_path)
texts = df["text_for_embedding"].tolist()
print(f"Generating embeddings for {len(texts)} texts using OpenAI...")
embeddings = openai_generate_embeddings(texts)
df["embedding"] = embeddings
records = []
for row in df.itertuples():
records.append((
row.id,
row.embedding,
{
"url": getattr(row, "url", ""), # safe get url if present
"text": row.text_for_embedding
}
))
pinecone_index.upsert(vectors=records, namespace=namespace)
print(f"Upserted {len(records)} records to Pinecone index '{index_name}'.")
Note: You only need to run this step once to populate the database. Afterward, you can comment out this part of the code.
Note: You only need to run this step once to populate the database. Afterward, you can comment out this part of the code.
3.9 Initialize the Pinecone search function
def pinecone_search(index, query, namespace=namespace, top_k=3, score_threshold=0.8, embedding_model=None):
# OpenAI embedding here
query_embedding = openai_generate_embeddings([query])[0]
results = index.query(
vector=query_embedding,
top_k=top_k,
namespace=namespace,
include_metadata=True,
)
filtered = []
for match in results.matches:
if match.score >= score_threshold:
filtered.append({
"score": match.score,
"url": match.metadata.get("url", ""),
"text": match.metadata.get("text", ""),
})
return filtered
Note: The score threshold defines the minimum similarity score for a result to be considered relevant. You can adjust this value based on your needs. The higher the score, the more accurate the result.
Note:
The score threshold defines the minimum similarity score for a result to be considered relevant. You can adjust this value based on your needs. The higher the score, the more accurate the result.
3.10 Generate answers using OpenAI
Use OpenAI to generate answers from the context retrieved via Pinecone.
# OpenAI answer generation
def openai_generate_answer(openai_api_key, query, context=None):
import openai
openai.api_key = openai_api_key
prompt_context = ""
if context:
prompt_context = "\\n\\nContext:\\n" + "\\n\\n".join(context)
prompt = f"Answer the following question: {query}" + prompt_context
response = openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
max_tokens=256,
temperature=0.7,
)
answer = response.choices[0].message.content.strip()
return answer
3.11 (Optional) Run a simple test to query and print results
Include CLI-friendly code that allows you to run a basic test. The test will help verify that your implementation is working and show a preview of the data stored in the database.
def search_news_and_answer(openai_api_key, query):
results = pinecone_search(pinecone_index, query)
if results:
print(f"Found {len(results)} relevant documents.")
print("Top documents:")
for doc in results:
print(f"Score: {doc['score']:.4f}")
print(f"URL: {doc['url']}")
print(f"Text (excerpt): {doc['text'][:250]}...\\n")
answer = openai_generate_answer(openai_api_key, query, [r["text"] for r in results])
print("\\nGenerated answer:\\n", answer)
if __name__ == "__main__":
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI key here or pass via arguments/env var
test_query = "What is wrong with Man City?"
search_news_and_answer(OPENAI_API_KEY, test_query)
Tip: You can control the amount of text shown by slicing the result, for example:
[:250].
Tip: You can control the amount of text shown by slicing the result, for example:
[:250].
Now your data is stored in the vector database. This means you have two query options:
Retrieve from the database
Use a generic response generated by OpenAI
Step 4: Build the Agent Controller
4.1 In agent_controller.py
Import the necessary functionality from
rag.py
.
from rag import openai_generate_answer, pinecone_search
4.2 Implement Pinecone retrieval
Add logic to retrieve relevant data from the Pinecone vector store.
def agent_controller_decide_and_act(
pinecone_api_key,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
print(f"Agent received query: {query}")
try:
print("Trying Pinecone retrieval...")
results = pinecone_search(pinecone_index, query, namespace=namespace)
if results:
print(f"Found {len(results)} matching documents in Pinecone.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
return answer
else:
print("No good matches found in Pinecone. Falling back to OpenAI generator.")
except Exception as e:
print(f"Pinecone retrieval failed: {e}")
4.3 Implement fallback OpenAI response
Create logic to generate an answer using OpenAI when no relevant context is retrieved.
try:
print("Generating answer from OpenAI without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
return answer
except Exception as e:
print(f"OpenAI generation failed: {e}")
return "Sorry, I am currently unable to answer your query."
Step 5: Put It All Together
5.1 In crux.py
Import all necessary functions from
agent_controller.py
.
from rag import pinecone_index # Import Pinecone index & embedding model
from rag import openai_generate_answer, pinecone_search # Import helper functions if needed
from agent_controller import agent_controller_decide_and_act # Your orchestration function
5.2 Provide your API keys
Make sure your OpenAI and Pinecone API keys are properly set.
# Your actual API keys here - replace with your real keys
PINECONE_API_KEY = "PINECONE_API_KEY"
OPENAI_API_KEY = "OPENAI_API_KEY"
5.3 Enter your prompt in the main() function
Define the prompt input inside the
main()
function.
def main():
query = "What is the problem with Man City?"
answer = agent_controller_decide_and_act(
pinecone_api_key=PINECONE_API_KEY,
openai_api_key=OPENAI_API_KEY,
pinecone_index=pinecone_index,
query=query,
namespace="default"
)
print("\\nAgent's answer:\\n", answer)
if __name__ == "__main__":
main()
5.4 Call the Agentic RAG
Run the Agentic RAG logic. You will see how it processes a query by first checking its relevance before querying the vector database.

Agent received query: What exactly is the problem with Man City Women Team?
Trying Pinecone retrieval...
Found 1 matching documents in Pinecone.
Agent's answer:
The problems with the Man City Women Team this season include a significant injury crisis, managerial upheaval, and poor performances in key games. Key players such as Vivianne Miedema, Khadija Shaw, Lauren Hemp, and Alex Greenwood have been sidelined due to injuries, which has severely impacted the team's performance and highlighted a lack of squad depth. Interim manager Nick Cushing suggests that the number of injuries is not solely down to bad luck or bad practice and calls for an examination of the situation.
Try testing it with a query that does not match your database, such as:
def main():
query = "Why Sleep?"
The agent determines that no good matches are found in Pinecone and falls back to generating a generic response using OpenAI.

the agent replies that is no good match with a generic response using chatgpt
Agent received query: Why Sleep?
Trying Pinecone retrieval...
No good matches found in Pinecone. Falling back to OpenAI generator.
as a car crash), or it can harm you over time.
For example, ongoing sleep deficiency can raise your risk for some chronic health problems. It also can affect how well you think, react, work, learn, and get along with as a car crash), or it can harm you over time.
Tip: You can print the relevance score (score_threshold) for each prompt to understand the agent’s confidence level.
Tip: You can print the relevance score (score_threshold) for each prompt to understand the agent’s confidence level.
That is it! You have successfully built your Agentic RAG.
Step 6 (Optional):Feedback Loop and Optimization
You can enhance your system by implementing a feedback loop to improve training and indexing over time.
6.1 Add a feedback function
In
agent_controller.py
, create a function that asks the user for feedback after a response is shown. You can call this function at the end of the main runner in
crux.py
.
def collect_user_feedback():
feedback = input("Was the answer helpful? (yes/no): ").strip().lower()
comments = input("Any comments or corrections? (optional): ").strip()
return feedback, comments
6.2 Implement feedback logic
Create a new function in
agent_controller.py
that reinvokes the retrieval process if the feedback is negative. Then, call this function in
crux.py:
def agent_controller_handle_feedback(
feedback,
comments,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
if feedback == "no":
print("Feedback: answer not helpful. Retrying with relaxed retrieval parameters...")
# Relaxed retrieval - increase number of docs and lower score threshold
results = pinecone_search(
pinecone_index,
query,
namespace=namespace,
top_k=5,
score_threshold=0.3
)
if results:
print(f"Found {len(results)} documents after retry.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
print("\\nNew answer based on feedback:\\n", answer)
return answer
else:
print("No documents found even after retry. Generating answer without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
print("\\nAnswer generated without retrieval:\\n", answer)
return answer
else:
print("Thank you for your positive feedback!")
return None
Conclusion and Next Steps
In this article, you built an autonomous Agentic RAG system that combines Bright Data for web scraping, Pinecone as a vector database, and OpenAI for text generation. This system provides a foundation that can be extended to support a variety of additional features, such as:
Integrating vector databases with relational or non-relational databases
Creating a user interface using Streamlit
Automating web data retrieval to keep training data up to date
Enhancing retrieval logic and agent reasoning
As demonstrated, the quality of the Agentic RAG system’s output depends heavily on the quality of the input data. Bright Data played a key role in enabling reliable and fresh web data, which is essential for effective retrieval and generation.
Consider exploring further enhancements to this workflow and using Bright Data in your future projects to maintain consistent, high-quality input data.