
Build a Web Scraping App with Lovable, Supabase & Bright Data
Building a reliable web data extraction solution starts with the right infrastructure. In this guide, you’ll create a single-page application that accepts any public webpage URL and a natural language prompt. It then scrapes, parses, and returns clean, structured JSON, fully automating the extraction process.
The stack combines Bright Data’s anti-bot scraping infrastructure, Supabase’s secure backend, and Lovable’s rapid development tools into one seamless workflow.
What you’ll build
Here’s the full data pipeline you’ll build – from user input to structured JSON output and storage:
User Input
↓
Authentication
↓
Database Logging
↓
Edge Function
↓
Bright Data Web Unlocker (Bypasses anti-bot protection)
↓
Raw HTML
↓
Turndown (HTML → Markdown)
↓
Clean structured text
↓
Google Gemini AI (Natural language processing)
↓
Structured JSON
↓
Database Storage
↓
Frontend Display
↓
User ExportHere’s a quick look at what the finished app looks like:
User authentication: Users can securely sign up or log in using the auth screen powered by Supabase.
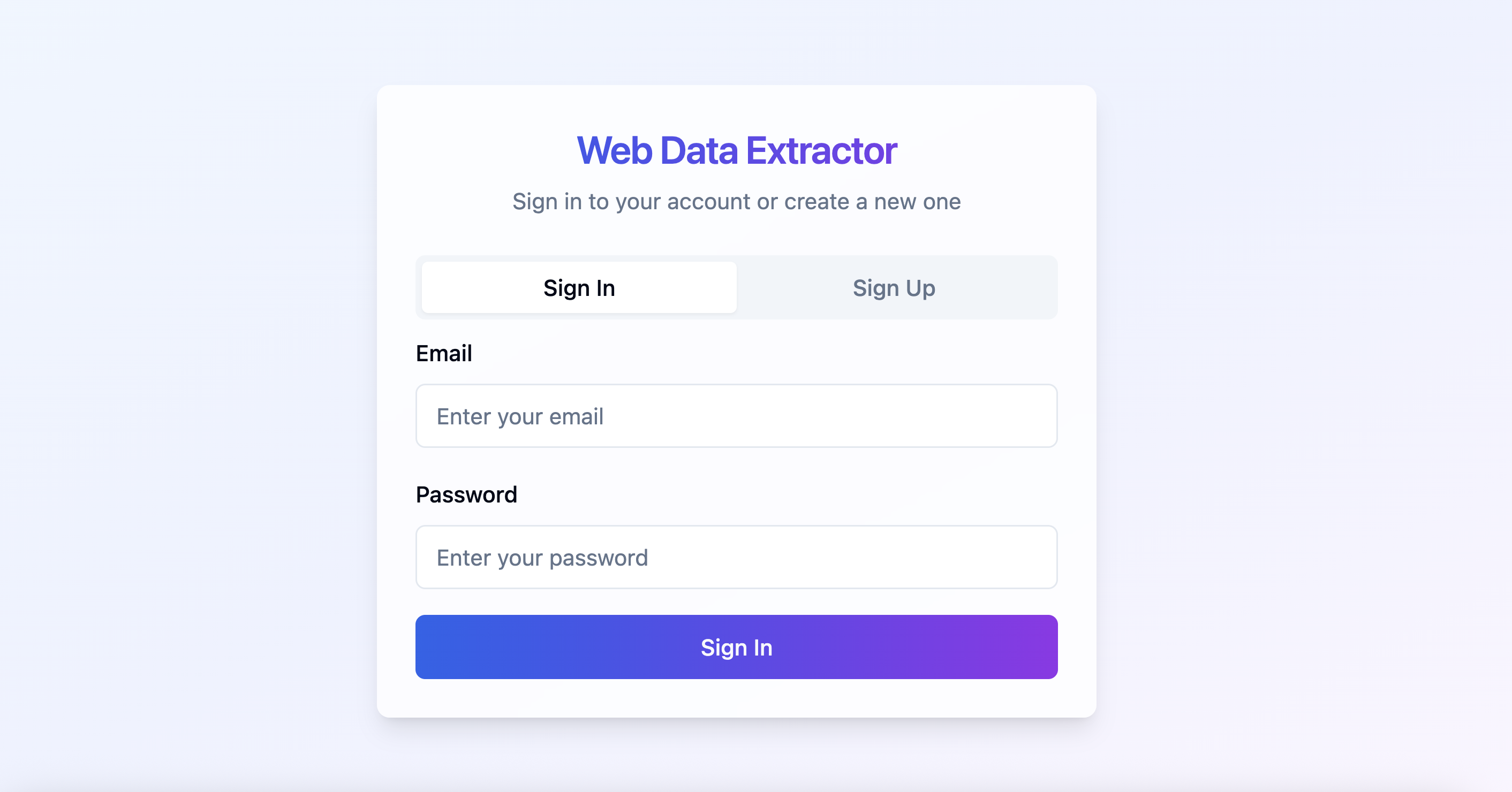
web-data-extractor-signin-form
Data extraction interface: After signing in, users can enter a webpage URL and a natural language prompt to retrieve structured data.
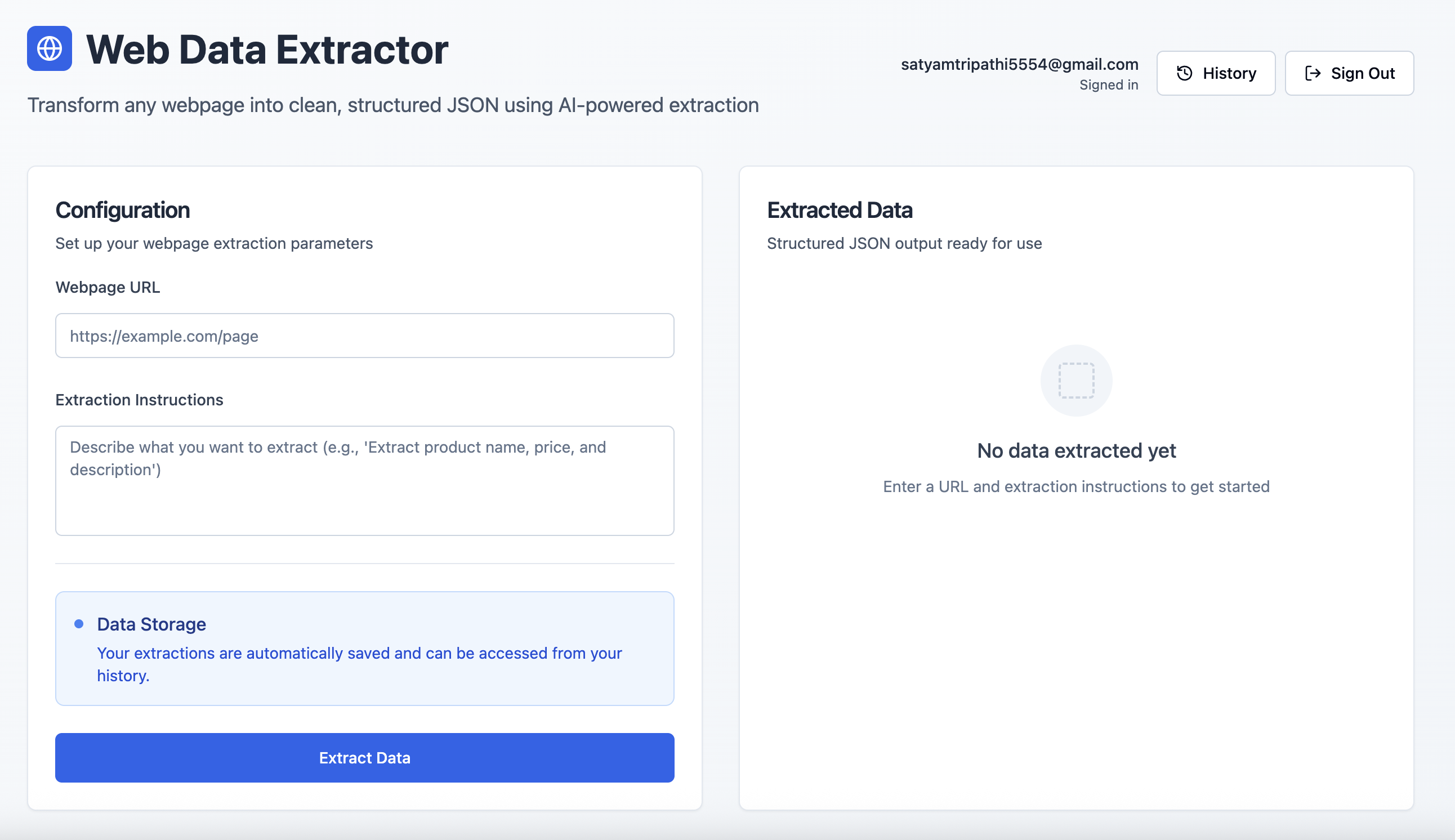
web-data-extractor-main-dashboard
Technology stack overview
Here’s a breakdown of our stack and the strategic advantage each component provides.
Bright Data: Web scraping often runs into blocks, CAPTCHAs, and advanced bot detection. Bright Data is purpose-built to handle these challenges. It offers: Automatic proxy rotation CAPTCHA solving and bot protection Global infrastructure for consistent access JavaScript rendering for dynamic content Automated rate limit handling For this guide, we’ll use Bright Data’s Web Unlocker — a purpose-built tool that reliably fetches full HTML from even the most protected pages.
Supabase: Supabase provides a secure backend foundation for modern apps, featuring: Built-in auth and session handling A PostgreSQL database with real-time support Edge Functions for serverless logic Secure key storage and access control
Lovable : Lovable streamlines development with AI-powered tools and native Supabase integration . It offers: AI-driven code generation Seamless front-end/backend scaffolding React + Tailwind UI out of the box Fast prototyping for production-ready apps
Google Gemini AI: Gemini turns raw HTML into structured JSON using natural language prompts. It supports: Accurate content understanding and parsing Large input support for full-page context Scalable, cost-efficient data extraction
Automatic proxy rotation
CAPTCHA solving and bot protection
Global infrastructure for consistent access
JavaScript rendering for dynamic content
Automated rate limit handling
For this guide, we’ll use Bright Data’s Web Unlocker — a purpose-built tool that reliably fetches full HTML from even the most protected pages.
Built-in auth and session handling
A PostgreSQL database with real-time support
Edge Functions for serverless logic
Secure key storage and access control
AI-driven code generation
Seamless front-end/backend scaffolding
React + Tailwind UI out of the box
Fast prototyping for production-ready apps
Accurate content understanding and parsing
Large input support for full-page context
Scalable, cost-efficient data extraction
Prerequisites and setup
Before starting development, make sure you have access to the following:
Bright Data account Sign up at brightdata.com Create a Web Unlocker zone Get your API key from the account settings
Google AI Studio account Visit Google AI Studio Create a new API key
Supabase project
Sign up at
supabase.com
Create a new organization
, then set up a new project
In your project dashboard, go to
Edge Functions
→
Secrets
→
Add New Secret.
Add secrets like
BRIGHT_DATA_API_KEY
and
GEMINI_API_KEY
with their respective values
Lovable account Register at lovable.dev Go to your profile → Settings → Integrations Under Supabase , click Connect Supabase Authorize API access and link it to the Supabase organization you just created
Sign up at brightdata.com
Create a Web Unlocker zone
Get your API key from the account settings
Visit Google AI Studio
Create a new API key
Sign up at supabase.com
Create a new organization , then set up a new project
In your project dashboard, go to
Edge Functions
→
Secrets
→
Add New Secret.
Add secrets like
BRIGHT_DATA_API_KEY
and
GEMINI_API_KEY
with their respective values
Register at lovable.dev
Go to your profile → Settings → Integrations
Under Supabase , click Connect Supabase
Authorize API access and link it to the Supabase organization you just created
Building the application step-by-step with Lovable prompts
Below is a structured, prompt-based flow for developing your web data extraction app, from frontend to backend, database, and intelligent parsing.
Lovable chat
Step #1 – frontend setup
Begin by designing a clean and intuitive user interface.
Build a modern web data extraction app using React and Tailwind CSS. The UI should include:
- A gradient background with card-style layout
- An input field for the webpage URL
- A textarea for the extraction prompt (e.g., "Extract product title, price, and ratings")
- A display area to render structured JSON output
- Responsive styling with hover effects and proper spacingStep #2 – connect Supabase & add authentication
To link your Supabase project:
Click the Supabase icon in the top-right corner of Lovable
Select Connect Supabase
Choose the organization and project you previously created
Lovable will integrate your Supabase project automatically. Once linked, use the prompt below to enable authentication:
Set up complete Supabase authentication:
- Sign up and login forms using email/password
- Session management and auto-persistence
- Route protection for unauthenticated users
- Sign out functionality
- Create user profile on signup
- Handle all auth-related errorsLovable will generate the required SQL schema and triggers – review and approve them to finalize your auth flow.
Step #3 – define Supabase database schema
Set up the required tables to log and store the extraction activity:
Create Supabase tables for storing extractions and results:
- extractions: stores URL, prompt, user_id, status, processing_time, error_message
- extraction_results: stores parsed JSON output
Apply RLS policies to ensure each user can only access their own dataStep #4 – create Supabase Edge Function
This function handles the core scraping, conversion, and extraction logic:
Create an Edge Function called 'extract-web-data' that:
- Fetches the target page using Bright Data's Web Unlocker
- Converts raw HTML to Markdown using Turndown
- Sends the Markdown and prompt to Google Gemini AI (gemini-2.0-flash-001)
- Returns clean structured JSON
- Handles CORS, errors, and response formatting
- Requires GEMINI_API_KEY and BRIGHT_DATA_API_KEY as Edge Function secrets
Below is a reference implementation that handles HTML fetching using Bright Data, markdown conversion with Turndown, and AI-driven extraction with Gemini:
import { GoogleGenerativeAI } from '@google/generative-ai';
import TurndownService from 'turndown';
interface BrightDataConfig {
apiKey: string;
zone: string;
}
// Constants
const GEMINI_MODEL = 'gemini-2.0-flash-001';
const WEB_UNLOCKER_ZONE = 'YOUR_WEB_UNLOCKER_ZONE';
export class WebContentExtractor {
private geminiClient: GoogleGenerativeAI;
private modelName: string;
private htmlToMarkdownConverter: TurndownService;
private brightDataConfig: BrightDataConfig;
constructor() {
const geminiApiKey: string = 'GEMINI_API_KEY';
const brightDataApiKey: string = 'BRIGHT_DATA_API_KEY';
try {
this.geminiClient = new GoogleGenerativeAI(geminiApiKey);
this.modelName = GEMINI_MODEL;
this.htmlToMarkdownConverter = new TurndownService();
this.brightDataConfig = {
apiKey: brightDataApiKey,
zone: WEB_UNLOCKER_ZONE
};
} catch (error) {
console.error('Failed to initialize WebContentExtractor:', error);
throw error;
}
}
/**
* Fetches webpage content using Bright Data Web Unlocker service
*/
async fetchContentViaBrightData(targetUrl: string): Promise<string | null> {
try {
// Append Web Unlocker parameters to the target URL
const urlSeparator: string = targetUrl.includes('?') ? '&' : '?';
const requestUrl: string = `${targetUrl}${urlSeparator}product=unlocker&method=api`;
const apiResponse = await fetch('https://api.brightdata.com/request', {
method: 'POST',
headers: {
'Authorization': `Bearer ${this.brightDataConfig.apiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
zone: this.brightDataConfig.zone,
url: requestUrl,
format: 'raw'
})
});
if (!apiResponse.ok) {
throw new Error(`Web Unlocker request failed with status: ${apiResponse.status}`);
}
const htmlContent: string = await apiResponse.text();
return htmlContent && htmlContent.length > 0 ? htmlContent : null;
} catch (error) {
console.error('Failed to fetch webpage content:', error);
return null;
}
}
/**
* Converts HTML to clean Markdown format for better AI processing
*/
async convertToMarkdown(htmlContent: string): Promise<string | null> {
try {
const markdownContent: string = this.htmlToMarkdownConverter.turndown(htmlContent);
return markdownContent;
} catch (error) {
console.error('Failed to convert HTML to Markdown:', error);
return null;
}
}
/**
* Uses Gemini AI to extract specific information from markdown content
* Uses low temperature for more consistent, factual responses
*/
async extractInformationWithAI(markdownContent: string, userQuery: string): Promise<string | null> {
try {
const aiPrompt: string = this.buildAIPrompt(userQuery, markdownContent);
const aiModel = this.geminiClient.getGenerativeModel({ model: this.modelName });
const aiResult = await aiModel.generateContent({
contents: [{ role: 'user', parts: [{ text: aiPrompt }] }],
generationConfig: {
maxOutputTokens: 2048,
temperature: 0.1,
}
});
const response = await aiResult.response;
return response.text();
} catch (error) {
console.error('Failed to extract information with AI:', error);
return null;
}
}
private buildAIPrompt(userQuery: string, markdownContent: string): string {
return `You are a data extraction assistant. Below is some content in markdown format extracted from a webpage.
Please analyze this content and extract the information requested by the user.
USER REQUEST: ${userQuery}
MARKDOWN CONTENT:
${markdownContent}
Please provide a clear, structured response based on the user's request. If the requested information is not available in the content, please indicate that clearly.`;
}
/**
* Main extraction workflow: fetches webpage → converts to markdown → extracts with AI
*/
async extractDataFromUrl(websiteUrl: string, extractionQuery: string): Promise<string | null> {
try {
const htmlContent: string | null = await this.fetchContentViaBrightData(websiteUrl);
if (!htmlContent) {
console.error('Could not retrieve HTML content from URL');
return null;
}
const markdownContent: string | null = await this.convertToMarkdown(htmlContent);
if (!markdownContent) {
console.error('Could not convert HTML to Markdown');
return null;
}
const extractedInformation: string | null = await this.extractInformationWithAI(markdownContent, extractionQuery);
return extractedInformation;
} catch (error) {
console.error('Error in extractDataFromUrl:', error);
return null;
}
}
}
/**
* Example usage of the WebContentExtractor
*/
async function runExtraction(): Promise<void> {
const TARGET_WEBSITE_URL: string = 'https://example.com';
const DATA_EXTRACTION_QUERY: string = 'Extract the product title, all available prices, ...';
try {
const contentExtractor = new WebContentExtractor();
const extractionResult: string | null = await contentExtractor.extractDataFromUrl(TARGET_WEBSITE_URL, DATA_EXTRACTION_QUERY);
if (extractionResult) {
console.log(extractionResult);
} else {
console.log('Failed to extract data from the specified URL');
}
} catch (error) {
console.error(`Application error: ${error}`);
}
}
// Execute the application
runExtraction().catch(console.error);Converting raw HTML to Markdown before sending it to Gemini AI has several key advantages. It removes unnecessary HTML noise, improves AI performance by providing cleaner, more structured input, and reduces token usage, leading to faster, more cost-efficient processing.
Important consideration:
Lovable is great at building apps from natural language, but it may not always be aware of how to properly integrate external tools like
Bright Data
or
Gemini
. To ensure accurate implementation, include a sample working code in your prompts. For example, the
fetchContentViaBrightData
The method in the above prompt demonstrates a simple use case for Bright Data’s Web Unlocker.
Bright Data offers several APIs – including Web Unlocker , SERP API , and Scraper APIs – each with its endpoint, authentication method, and parameters. When you set up a product or zone in the Bright Data dashboard, the Overview tab provides language-specific code snippets (Node.js, Python, cURL) tailored to your configuration. Use those snippets as-is or adapt them to fit your Edge Function logic.
Step #5 – connect frontend to Edge Function
Once your Edge Function is ready, integrate it into your React app:
Connect the frontend to the Edge Function:
- On form submission, call the Edge Function
- Log the request in the database
- Update status (processing/completed/failed) after the response
- Show processing time, status icons, and toast notifications
- Display the extracted JSON with loading statesStep #6 – add extraction history
Provide users with a way to review previous requests:
Create a history view that:
- Lists all extractions for the logged-in user
- Displays URL, prompt, status, duration, and date
- Includes View and Delete options
- Expands rows to show extracted results
- Uses icons for statuses (completed,failed,processing)
- Handles long text/URLs gracefully with a responsive layoutStep #7 – UI polish and final enhancements
Refine the experience with helpful UI touches:
Polish the interface:
- Add toggle between "New Extraction" and "History"
- Create a JsonDisplay component with syntax highlighting and copy button
- Fix responsiveness issues for long prompts and URLs
- Add loading spinners, empty states, and fallback messages
- Include feature cards or tips at the bottom of the pageConclusion
This integration brings together the best of modern web automation: secure user flows with Supabase, reliable scraping via Bright Data, and flexible, AI-powered parsing with Gemini – all powered through Lovable’s intuitive, chat-based builder for a zero-code, high-productivity workflow.
Ready to build your own? Get started at brightdata.com and explore Bright Data’s data collection solutions for scalable access to any site, with zero infrastructure headaches.