
BeautifulSoup Web Scraping: Step-By-Step Tutorial
Web scraping is the automated process of extracting data from websites using scripts or software tools to retrieve information, typically for analysis or aggregation.
Beautiful Soup is a popular Python library for efficiently parsing HTML and XML documents.
In this comprehensive guide, you’ll learn how to use Beautiful Soup for web scraping. Packed with code samples and practical advice, this article provides valuable insights throughout the learning process.
Web Scraping with Beautiful Soup
Typically, HTML and XML languages are used for structuring web content, and a Document Object Model (DOM) tree represents the document as a tree of objects. You can use automated scripts or libraries to extract meaningful information from the web content by navigating its DOM.
The Beautiful Soup Python library can parse HTML and XML documents and navigate the DOM tree. The library automatically selects the best HTML parser on your device, or you can specify a custom HTML parser. Then the library converts the HTML document into a navigable tree of Python objects.
Beautiful Soup also lets you parse XML content using a fast and efficient lxml parser. Similar to HTML documents, the library generates a tree of Python objects from the XML document that can be used to traverse the document using Beautiful Soup selectors.
The Beautiful Soup HTML or XML parser can be used to parse web content and generate Python objects that resemble a DOM tree. The generated Python object can be used to extract data from different parts of the document efficiently by selecting the relevant elements. There are several approaches for selecting elements, including
find()
, which takes a selector condition and returns the first matching HTML element, and
find_all()
, which takes a selector condition and returns a list of all matching HTML elements. For example, you can find all contents within the paragraph (
<p>
) tags using the
find_all('p')
selector.
Using Beautiful Soup for Web Scraping
Before you start scraping data from web pages, you need to identify what data you want to scrape on the page and how you’re going to scrape it.
You can use your web browser’s developer tools to inspect elements on the web page. For example, the following screenshot shows the DOM elements for the quotes block on the Quotes to Scrape web page:
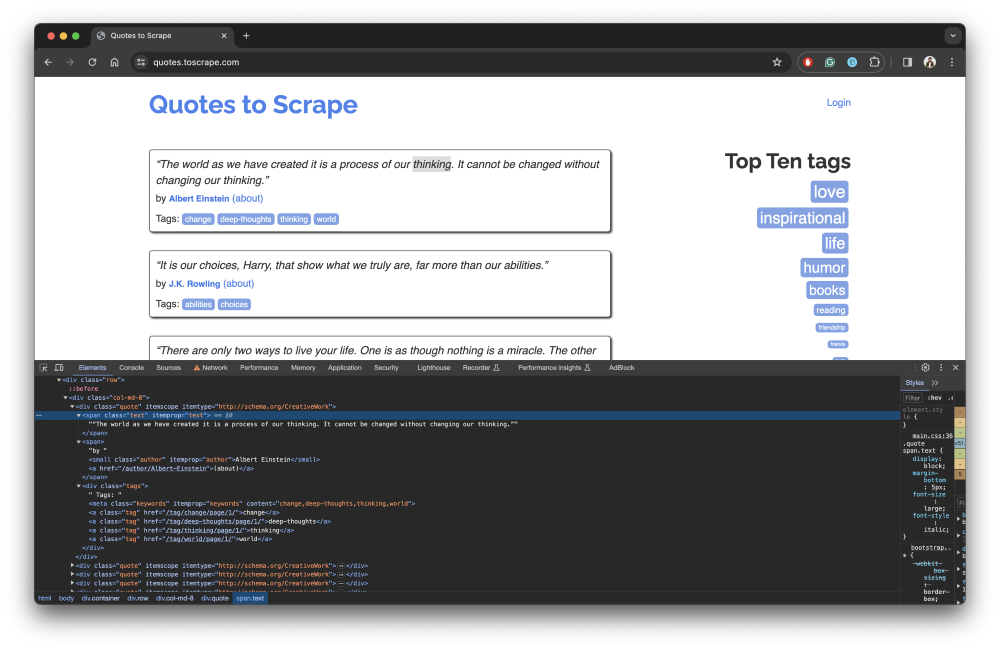
Quotes to scrape
Notice that the quote text is within a
span
tag and the author name is within the
small
tag. In addition to tags, you can use a combination of
HTML attributes and CSS selectors
to select certain elements. In this guide, you’ll scrape quotes and author names from the
Quotes to Scrape
page.
Create a New Project
To begin, create a new project directory named
beautifulsoup-scraping-example
for the scraping scripts and navigate to it using the following commands:
mkdir beautifulsoup-scraping-example
cd beautifulsoup-scraping-example
When web scraping, you need to first fetch the web page contents from a URL using an HTTP
GET
request. Install the
requests library
with the following command:
pip install requests
You’ll use this library to make
GET
requests later.
For the actual web scraping task, install the beautifulsoup4 Python library using the following command:
pip install beautifulsoup4
You could also store the list of dependencies in a file to collaborate on the script or check it in a version control system. Create a
requirements.txt
file in the project root with the following contents:
requests
beautifulsoup4
Then install the dependencies defined in the file earlier using this command:
pip install -r requirements.txt
Define Your Web Scraping Script
Next, you need to define a Python script that fetches the web page contents and parses it using
BeautifulSoup
to generate a
soup
object. You can use different selectors with the
soup
object to find elements on the web page and extract the desired information from it.
Start by creating a Python script file called
main.py
in your project’s root and add
import
statements for
requests
and
beautifulsoup4
:
import requests
from bs4 import BeautifulSoup
Next, define a method that takes a web URL and returns the page contents:
def get_page_contents(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
page = requests.get(url, headers=headers)
if page.status_code == 200:
return page.text
return None
Notice that the
get_page_contents
method uses the
requests
library to call a
GET
method and returns the
text
response. Additionally, note that the method passes the
User-Agent
header request along with the
GET
request to avoid receiving an error response from the web server. Passing the
User-Agent
header is optional, but some web servers might reject the request if they receive an unknown user agent.
To scrape quotes and authors from the page contents, define a method that uses
BeautifulSoup
to parse the raw HTML data and return the desired data:
def get_quotes_and_authors(page_contents):
soup = BeautifulSoup(page_contents, 'html.parser')
quotes = soup.find_all('span', class_='text')
authors = soup.find_all('small', class_='author')
return quotes, authors
Here, the method takes the
page_contents
obtained from the
get_page_contents
method. It creates an instance of
BeautifulSoup
using the page contents and specifies the type of parser to be used. If you omit the second argument, Beautiful Soup automatically uses the best parser installed on the device based on the page contents.
Then it uses the
soup
instance to find all elements for quotes and authors and uses the
find_all
method to select the elements based on the tags. Finally, it specifies a CSS selector for refining the search criteria.
Now, put everything together and add the following code snippet at the end of the
main.py
file:
if __name__ == '__main__':
url = 'http://quotes.toscrape.com'
page_contents = get_page_contents(url)
if page_contents:
quotes, authors = get_quotes_and_authors(page_contents)
for i in range(len(quotes)):
print(quotes[i].text)
print(authors[i].text)
print()
else:
print('Failed to get page contents.')
This code uses the
get_page_contents
to fetch the page contents, and it uses the page contents to get all the
quotes
and
authors
using the
get_quotes_and_authors
method. Finally, it iterates over the list of quotes and prints the results.
Test the script by executing the following command:
python main.py
Your output should look like this:
"The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking."
Albert Einstein
--- OUTPUT OMITTED ---
"A day without sunshine is like, you know, night."
Steve Martin
As you can see, you’ve now successfully created a scraping script. If you’re interested in learning more, check out web sraping with Python guide, which includes some more advanced scraping techniques.
All the code used here is available in this GitHub repo .
Handling Common Challenges
Depending on the complexity of the web page you’re trying to scrape, you may encounter some challenges when scraping, including the following:
Dynamic Content
Some websites load content dynamically using JavaScript instead of rendering it statically (like the Quotes to Scrape web page you used here). For example, the Scraping Sandbox home page lists a JavaScript version of the same web page that is dynamically rendered. Now, see if the script you created works on this dynamic content.
Replace the
url
in the
main.py
script with the following:
# update URL in the main.py script
url = 'https://quotes.toscrape.com/js/'
Then execute the script. You’ll notice that the output is empty.
If you want to render and scrape dynamic content, you have to use a headless browser like Selenium. A headless browser runs without a graphical user interface (GUI) and works by allowing automated manipulation of a web page within an environment resembling widely used web browsers. Selenium lets you scrape web pages that rely on JavaScript by utilizing a genuine browser to render the web pages.
Pagination
In addition to having dynamic content, web pages can also have pagination implemented in several different ways. Before you scrape any data, you need to understand how pagination was implemented on the website you’re trying to scrape.
Common techniques for pagination include the following:
Markers or URL Patterns
The web page could contain markers for
Previous
and
Next
pages with URLs. Additionally, the website might follow a specific pattern for paginated content. For example, the
Quotes to Scrape
page has a
Next
page marker at the bottom.
You can use the Beautiful Soup library to
find
the next page marker and get its relative link to construct the URL for the next page and scrape its data.
Infinite Scrolling
Infinite scrolling is when a web page loads more content as you scroll down. For example, the ToScrape website has a scroll version of the Quotes to Scrape page that loads more quotes as you scroll. For web pages like this, you have to use a headless browser with scrolling capabilities. You can use Selenium’s scroll wheel action to scroll the web page and load more content.
Error Handling
Sometimes, during web scraping, the desired elements might be missing or contain dirty data. Handling these scenarios is critical to ensure consistent results.
Wrapping your scraper’s code in a
try-catch
block prevents your script from crashing when it encounters unexpected errors. For instance, on the
Quotes to Scrape
website, the author’s name could be missing from some of the quotes. You can modify the
get_quotes_and_authors
method to add a
try-catch
block to catch and log the error:
def get_quotes_and_authors(page_contents):
soup = BeautifulSoup(page_contents, 'html.parser')
try:
quotes = soup.find_all('span', class_='text')
authors = soup.find_all('small', class_='author')
except Exception as e:
print(e)
return None, None
return quotes, authors
Bonus Section – Tips and Tricks
In this section, we will cover a few interesting tricks that can help you optimize the process of scraping with Beautiful Soup.
Finding All The Used Tags in a Document
To find HTML tags, you can utilize libraries like Beautiful Soup in Python. One approach is to read an HTML file using Beautiful Soup and then extract a list of all the tags present in the file by iterating through its descendants. By using the
soup.descendants
generator provided by Beautiful Soup, you can access and print each tag’s name that is part of the HTML structure. This process involves opening the HTML file, parsing it with Beautiful Soup, and then iterating through its descendants to identify and display the names of the HTML tags encountered in the document.
Extract The Full Content From HTML Tags
Here is a step-by-step guide on how to perform this operation:
Begin by importing the necessary library, BeautifulSoup, which is used for parsing HTML and XML documents.
Open the HTML file containing the content you want to extract. You can do this using Python’s file handling capabilities. Read the contents of the file and store them in a variable.
Create a BeautifulSoup object by providing the contents of the HTML file along with the specified parser (in this case, “html.parser”).
Once you have the BeautifulSoup object created, you can access specific HTML tags within the document using its tag names as attributes. For example, if you want to extract the content within an h2 tag, you can access it using
soup.h2
.
Similarly, you can extract the content within paragraphs (
<p>
) and list items (
<li>
) by accessing them using
soup.p
and
soup.li
respectively.
Finally, by executing these instructions, you will be able to output the full content of the specified HTML tags in the order in which they appear in the document.
By following these steps and utilizing the BeautifulSoup library, you can effectively extract the complete content from HTML tags present in your HTML document.
Ethical Considerations
Before scraping any data, you must review and adhere to the website’s terms of service by defining your scripts per the restrictions defined. You should follow the rules defined in the target website’s
robot.txt
during scraping
.
Additionally, make sure you refrain from collecting personal information without obtaining consent as this can infringe upon privacy regulations.
You should also avoid aggressive scraping that can overload servers and impact the site’s performance. The web server might implement protective measures, such as enforcing rate limits, displaying CAPTCHAs, or blocking your IP address. If possible, provide attribution to the source website to acknowledge the effort and content provided by the website.
Optimizing Web Scraping
To improve the reliability and efficiency of your web scraping scripts, consider implementing some of the following techniques:
Use Parallelization
Consider leveraging parallelization in your scripts using multiple threads for processing nested data. For example, on the
Quotes to Scrape
web page, you can modify the script to find all the quote
div
blocks and process the
div
blocks in parallel. This technique can significantly improve a script’s execution speed if the DOM tree is complex.
Add Retry Logic
Adding a retry logic for network calls in the script could improve its reliability. For example, in this use case, you could add a retry logic for the
get_page_contents
to ensure that the script doesn’t fail if the page contents cannot be fetched the first time you try.
Rotate User Agents
If a web server receives a large number of requests from the same user agent, it may block your requests. To get around this issue, you can rotate the user agents by generating a new
User-agent
with every request. Notice that the
get_page_contents
method passes a static
User-agent
header to the
requests.get
API call. You can define a method called
get_random_user_agent
that generates a dynamic user agent.
Implement Rate Limiting
The web server might block or deny your requests if you send too many requests in a short time. To solve this issue, you can implement manual delays between requests.
Use a Proxy Server
You can use a proxy server as an intermediary between your scraping script and the target pages. A proxy server helps rotate the IP address while requesting to fetch the web page contents, avoiding IP bans. Learn more about Python IP rotation .
Bright Data offers multiple proxy networks, powerful web scrapers, and ready-to-use datasets for download. Bright Data also provides several proxy services , including residential, datacenter, ISP, and mobile proxies, to suit your web scraping requirements. If you’re looking to take your web scraping to the next level, consider doing so with Bright Data.
Conclusion
Beautiful Soup is a valuable tool for web scraping, and it seamlessly integrates with several different XML and HTML parsers. Once you identify the data you want to scrape and understand the web page’s structure, you can use the Beautiful Soup Python library to write a script quickly. However, depending on the complexity of the web page, you might need to handle challenges related to dynamic content, pagination, and errors.
If you’re looking to reduce your development effort and scale up your scraping, consider using the Serverless Functions product , which is built on top of the unblocking proxy infrastructure. It includes prebuilt JavaScript functions and code templates sourced from popular websites. Looking for a simple, auto-pilot solution with production-ready APIs? Try the new Web Scraping API .
Moreover, the Bright Data proxy services provide an advanced proxy infrastructure with efficient performance and the ability to bypass location restrictions with proxies from 195 countries . It’s compliant with the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), and it works with all the popular programming languages.