Agent Browser vs Puppeteer & Playwright: Key Differences
Browser automation tools have become essential for developers building web scrapers, bots, or AI agents that need to interact with websites. While open-source tools like Puppeteer and Playwright are widely used, Bright Data’s Agent Browser brings a different approach, one that’s built for stealth, scale, and AI-native workflows.
In this guide, you will learn:
How Agent Browser differs from Puppeteer and Playwright in stealth and fingerprinting.
The built-in features Bright Data provides, such as proxy rotation and automated session handling.
Scenarios where each tool excels or falls short.
The limitations of both Agent Browser and traditional frameworks, and when to choose one over the other.
Why Compare Agent Browser, Puppeteer & Playwright?
Browser automation has become a go-to solution for developers building scrapers, bots, and AI agents. Whether it’s collecting data from dynamic web pages, performing automated logins, or running repetitive tasks at scale, browser frameworks are now a critical part of modern development workflows.
Among the most popular tools in this space are Puppeteer and Playwright both open-source, Node.js-based libraries that provide a high-level API to control headless or full browsers. Puppeteer, maintained by the Chrome team, is known for its tight integration with Chromium and Playwright, developed by Microsoft, builds on that foundation by supporting multiple browsers (Chromium, Firefox, and WebKit) and enabling more advanced features like multi-page contexts and built-in waits. These tools have become widely adopted because of their flexibility and control, especially in scripting custom workflows.
However, as websites come up with increasingly aggressive bot-detection mechanisms, many developers find themselves spending more time dealing with challenges like fingerprinting, CAPTCHA solving, and proxy rotation than writing business logic. This is where our Agent Browser comes in.
Built specifically for AI agents and automation workflows, the Agent Browser abstracts away much of the low-level work that Puppeteer and Playwright users have to manage manually. It’s a full browser environment designed to mimic real users, with stealth, proxy management, session persistence, and CAPTCHA handling baked in. It’s part of Bright Data’s broader infrastructure for collecting web data at scale, and it’s designed to help developers focus on their automation goals rather than the plumbing required to stay undetected.
Key Differences: Stealth & Fingerprinting
One of the biggest challenges in browser automation today is avoiding detection. Websites are increasingly using sophisticated bot-detection systems that monitor everything from browser fingerprint mismatches to mouse movement patterns etc. This is where tools like Puppeteer and Playwright start to show their limits.
Out of the box, Puppeteer and Playwright do not come with stealth or anti-detection features. Developers often have to manually patch in tools like
puppeteer-extra-plugin-stealth
, rotate proxies, or modify headers and fingerprints just to stay under the radar. Even then, detection rates can remain high, especially on sites with advanced bot protection.
Agent Browser, on the other hand, was designed with stealth as a first-class feature. It runs cloud-based headful browser sessions that mimic real user behavior, complete with human-like fingerprints, natural scrolling and interaction patterns, and smart header control. Every session is launched with realistic browser characteristics that align with the location, device type, and browser version being emulated.
Here’s what it does out of the box:
Fingerprint spoofing : Agent Browser creates browser fingerprints that resemble real user environments (unlike default headless signatures).
CAPTCHA solving : It automatically handles challenges when a CAPTCHA appears, reducing interruptions in automated flows.
Proxy rotation : It rotates IP addresses and retries requests automatically if a block is detected.
Cookie and session tracking : It keeps session state and cookies persistent, reducing detection from repeated requests.
These features are especially critical when scraping websites with dynamic layouts, login gates, or personalized content. For example, an e-commerce store showing region-specific prices or availability. On platforms like that, even small inconsistencies in browser behavior can trigger blocks or empty responses. With Agent Browser, developers don’t need to manually configure stealth plugins or rotate proxies, it’s all managed in the background.
This tight integration with our proxy infrastructure also means developers can access content from specific geolocations, adjust referrer headers, and maintain long-lived sessions, making it a strong option for multi-step agent workflows.
Session Handling & Authentication
Session handling is mostly manual with Puppeteer and Playwright; developers must capture and reuse cookies or local storage, write logic for login persistence, authentication, and manage tokens or CSRF protection. This increases complexity, especially at scale.
Agent Browser automates session persistence and rotation. Cookies and local storage are managed automatically in the cloud, so session state is maintained across pages and tabs with no custom logic. If a session is blocked, a new one starts with a fresh IP and fingerprint. No retry or CAPTCHA handling code required.
This automation reduces IP bans, minimizes session failures, and lets developers focus on automation tasks instead of session management. It’s also integrated with Bright Data’s proxy network for consistent identity control.
Ease of Use & Developer Experience
One of the key factors developers weigh when choosing a browser automation tool is how quickly they can go from setup to first successful run. With Puppeteer and Playwright, getting started is straightforward if you’ve worked with headless browsers before. Installing the libraries, launching a browser instance, and navigating a page takes just a few lines of code. But the moment you need to add proxy support, CAPTCHA handling , fingerprinting , or session persistence, things get more complex. You’ll often need to install additional plugins, configure proxy libraries, manually manage cookies, and troubleshoot detection issues.
Agent Browser is designed to reduce that complexity. Integration can be done through the API or MCP with no need for per-site configuration. There is no need to maintain your own browser infrastructure; There’s no need to patch together stealth plugins or rotate IPs manually, everything is handled automatically in the background.
Developers can choose between a headful or headless experience, with programmatic control over the session from start to finish. For those who prefer code-based workflows, Agent Browser is compatible with Playwright, Puppeteer, and Selenium. The code samples below will help you plug it into you already existing stack with minimal friction.
JavaScript:
const pw = require('playwright');
const SBR_CDP = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222';
async function main() {
console.log('Connecting to Scraping Browser...');
// Scraping browswer here...
const browser = await pw.chromium.connectOverCDP(SBR_CDP);
try {
const page = await browser.newPage();
console.log('Connected! Navigating to <https://example.com>...');
await page.goto('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await page.content();
console.log(html);
} finally {
await browser.close();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
const puppeteer = require('puppeteer-core');
const SBR_WS_ENDPOINT = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222';
async function main() {
console.log('Connecting to Scraping Browser...');
const browser = await puppeteer.connect({
// Scraping browswer here...
browserWSEndpoint: SBR_WS_ENDPOINT,
});
try {
const page = await browser.newPage();
console.log('Connected! Navigating to <https://example.com>...');
await page.goto('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await page.content();
console.log(html)
} finally {
await browser.close();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
const { Builder, Browser } = require('selenium-webdriver');
const SBR_WEBDRIVER = '<https://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9515>';
async function main() {
console.log('Connecting to Scraping Browser...');
const driver = await new Builder()
.forBrowser(Browser.CHROME)
// Scraping browswer here...
.usingServer(SBR_WEBDRIVER)
.build();
try {
console.log('Connected! Navigating to <https://example.com>...');
await driver.get('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await driver.getPageSource();
console.log(html);
} finally {
driver.quit();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
Python:
import asyncio
from playwright.async_api import async_playwright
SBR_WS_CDP = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222'
async def run(pw):
print('Connecting to Scraping Browser...')
# Scraping browswer here...
browser = await pw.chromium.connect_over_cdp(SBR_WS_CDP)
try:
page = await browser.new_page()
print('Connected! Navigating to <https://example.com>...')
await page.goto('<https://example.com>')
print('Navigated! Scraping page content...')
html = await page.content()
print(html)
finally:
await browser.close()
async def main():
async with async_playwright() as playwright:
await run(playwright)
if __name__ == '__main__':
asyncio.run(main())
const puppeteer = require('puppeteer-core');
const SBR_WS_ENDPOINT = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222';
async function main() {
console.log('Connecting to Scraping Browser...');
const browser = await puppeteer.connect({
# Scraping browswer here...
browserWSEndpoint: SBR_WS_ENDPOINT,
});
try {
const page = await browser.newPage();
console.log('Connected! Navigating to <https://example.com>...');
await page.goto('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await page.content();
console.log(html)
} finally {
await browser.close();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
SBR_WEBDRIVER = '<https://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9515>'
def main():
print('Connecting to Scraping Browser...')
# Scraping browswer here...
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')
with Remote(sbr_connection, options=ChromeOptions()) as driver:
print('Connected! Navigating to <https://example.com>...')
driver.get('<https://example.com>')
print('Navigated! Scraping page content...')
html = driver.page_source
print(html)
if __name__ == '__main__':
main()
The goal is simple: eliminate the boilerplate setup, so developers can focus on what their automation needs to do, not how to keep it running reliably.
Under the Hood: Built-In Features with Bright Data
What makes Agent Browser different is what’s already included when the session launches.
Proxy rotation is handled automatically. Each session is backed by our extensive proxy network, which includes over 150 million residential IPs across 195 countries .
Browser fingerprinting is human-like by design, avoiding headless telltale signs and emulating real environments (down to device, OS, and browser version).
CAPTCHA solving is built-in, no external services required, no failed sessions hanging due to visual challenges.
Session persistence is consistent. Tabs, cookies, and local storage are preserved, which is critical for tasks like authenticated scraping or step-based workflows.
Referral and header control lets you simulate visits from known or trusted sources, helpful in situations where HTTP headers affect page delivery.
All of this is wrapped into a standardized, cloud-based environment, so you get consistent performance no matter where or when the session runs. It’s scalable, API-accessible, and tightly integrated with the broader data pipeline, so the output is immediately AI‑ready, structured or raw, real-time or batch.
Below is an overview of what you get in your dashboard after creating an account.
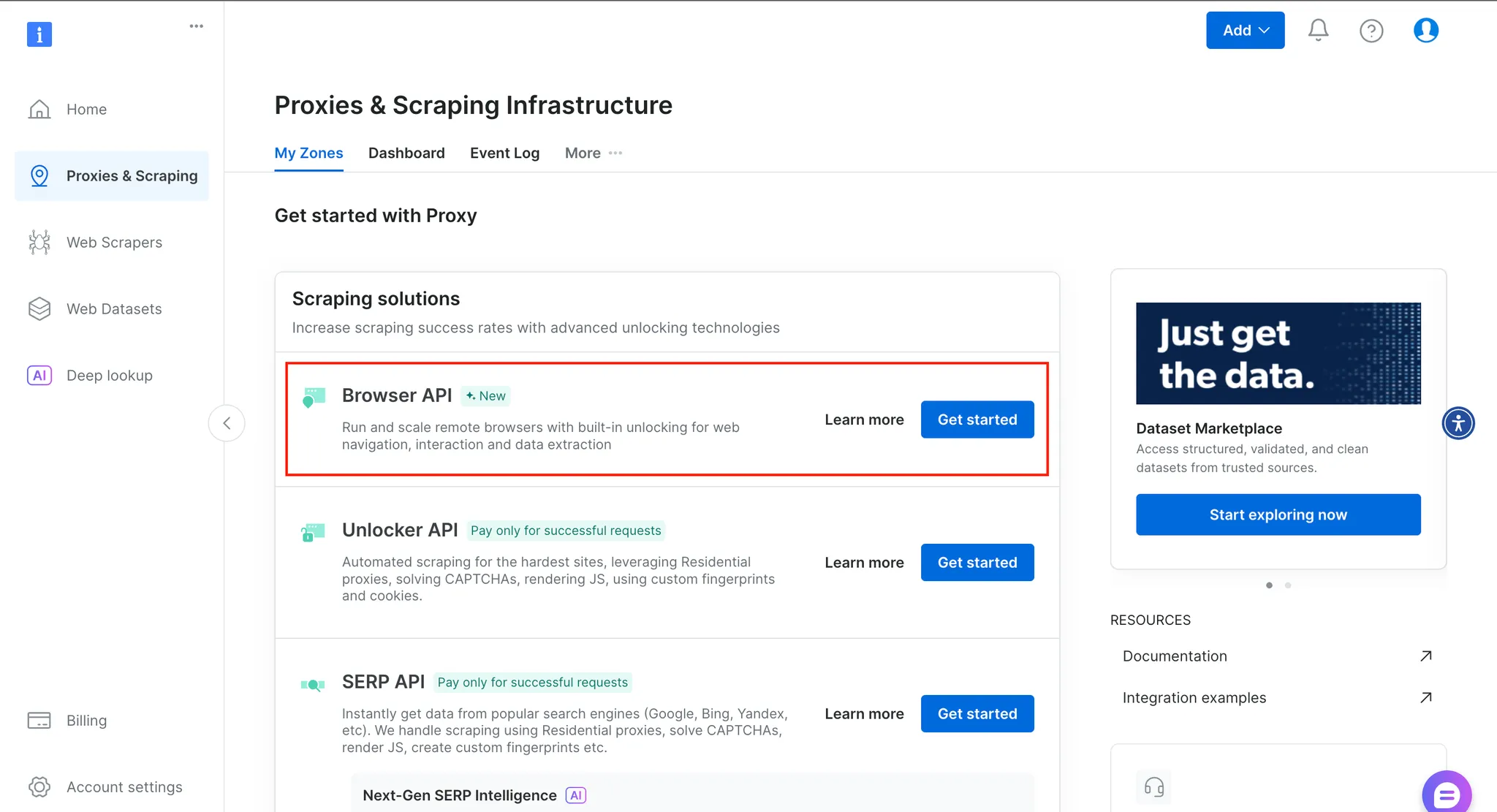
Clicking on learn more under the Browser API
After clicking on learn more you get more information, as seen below.
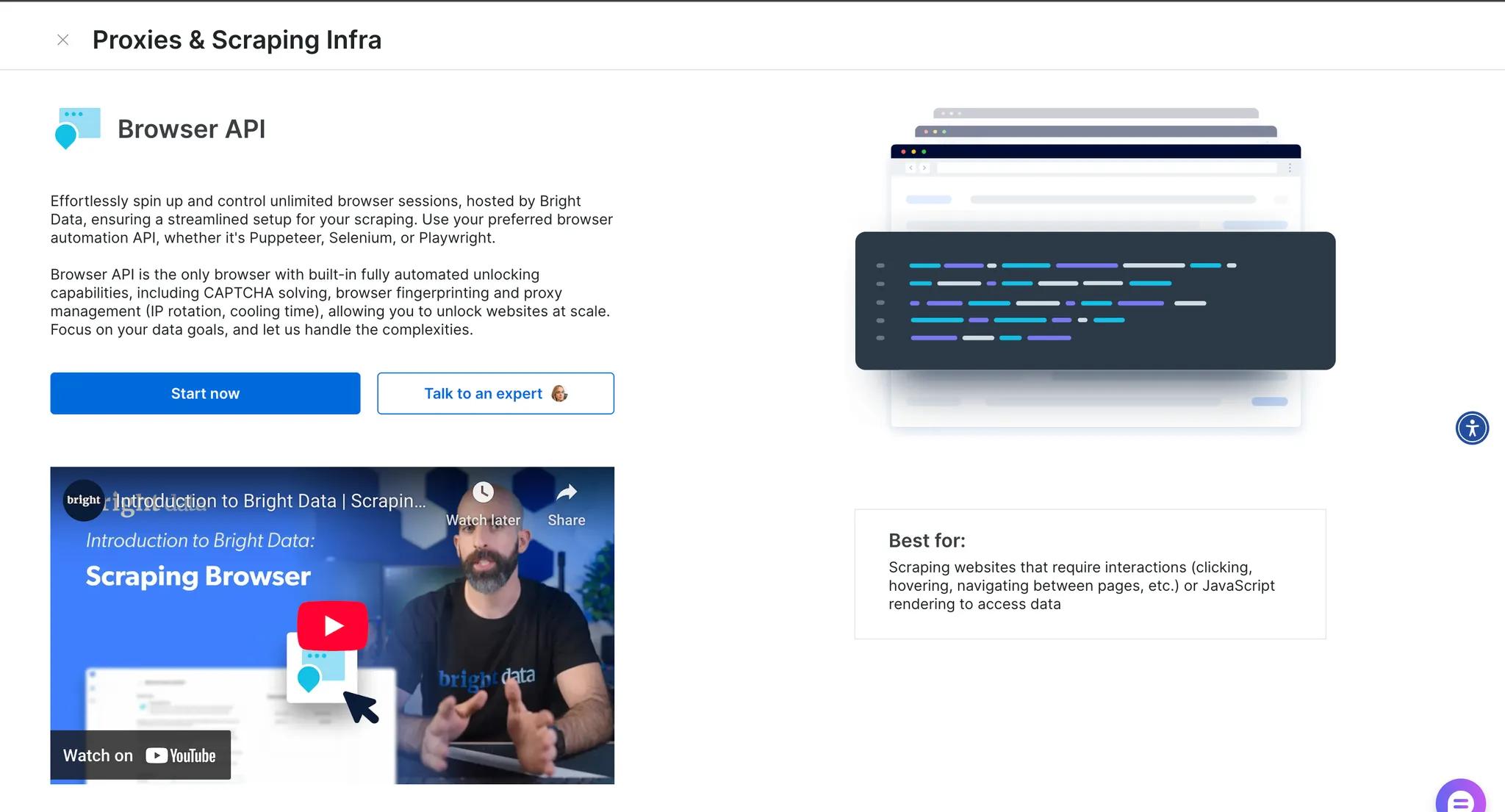
Additional information about Browser API
After clicking on start you get redirected where you can enter more information about your service and configure it accordingly, as seen below:
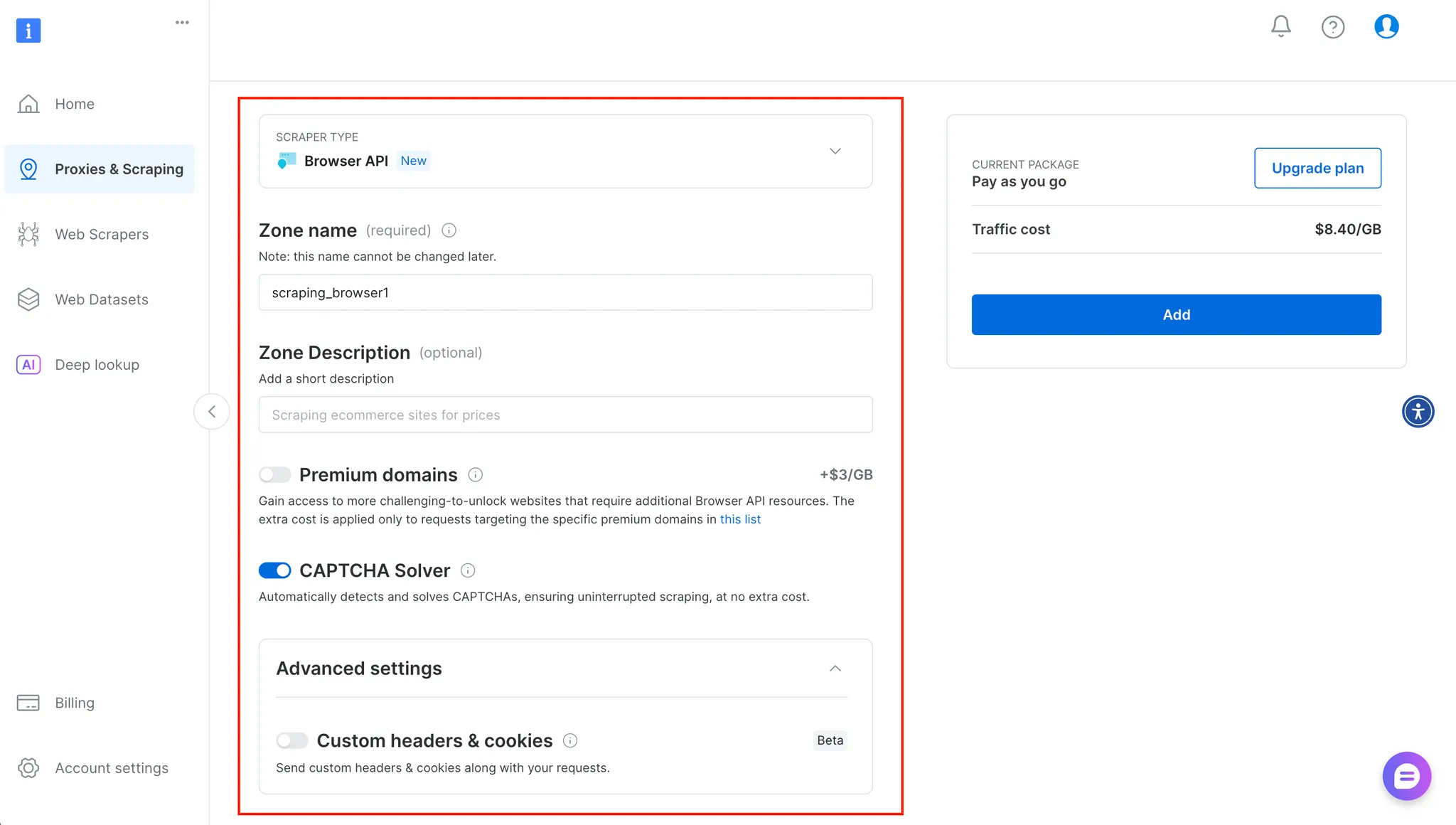
Configuring the new Browser API zone
Choosing the Right Tool: When Each Makes Sense
Each tool has its place, and understanding when to use one over the other can save time and frustration.
Use Agent Browser if:
You need to handle advanced anti-bot mechanisms without building custom stealth layers.
Your workflows involve multi-step tasks that require session persistence (e.g. logins, form submissions).
You want to launch and scale hundreds or thousands of browser sessions across different geolocations.
You’d rather focus on what the agent does, not how to manage its infrastructure.
Stick with Puppeteer or Playwright if:
Your task is small-scale, fast, and local, like a script that pulls a few headlines or automates testing in CI.
You want full control over the browser environment and don’t need built-in unblocking.
You’re operating in an offline or secure environment where using a remote browser isn’t possible.
In some cases, a hybrid approach works best. For example, you might run Playwright scripts locally but use Bright Data proxies to handle IP rotation and geotargeting . Or use the Web MCP for high-risk targets and open-source frameworks for low-friction scraping.
Limitations & Considerations
No tool is perfect, and each comes with trade-offs.
Agent Browser’s cloud-based nature means it’s not designed for offline use or environments where data locality is critical. For teams working in regulated industries or with restricted networks, running browsers locally may still be preferred.
Puppeteer and Playwright, while flexible, require constant maintenance as websites evolve. New bot-detection techniques or layout changes often break existing scripts, especially when stealth plugins fall out of date. And as the scale grows, maintaining browser infrastructure, rotating IPs, and preventing blocks can become a full-time concern.
It’s also worth considering that Agent Browser is built for public-facing websites and automation tasks aligned with ethical scraping. It is not intended for bypassing login walls without permission or scraping content behind paywalls.
Conclusion & Next Steps
Choosing between Agent Browser, Puppeteer, and Playwright comes down to what your workflow demands. If you need stealth, scale, and simplicity, Agent Browser delivers automation without the hassle. If you’re building something fast and local with full control, Puppeteer and Playwright are solid options. In either case, understanding how they differ, especially around session management, fingerprinting, and infrastructure, can help you avoid wasted time and broken flows.
You can explore Agent Browser or connect it to your existing automation stack using Playwright, Puppeteer, or even MCP. For more background, check out our guide on web scraping with ChatGPT or building agents with MCP .